|
|
| 635번째 줄: |
635번째 줄: |
| | [[File:Arirang 사전.zip|Arirang 사전.zip]] [http://www.jopenbusiness.com/mediawiki/images/5/54/Arirang_사전.zip http://www.jopenbusiness.com/mediawiki/images/5/54/Arirang_사전.zip] | | [[File:Arirang 사전.zip|Arirang 사전.zip]] [http://www.jopenbusiness.com/mediawiki/images/5/54/Arirang_사전.zip http://www.jopenbusiness.com/mediawiki/images/5/54/Arirang_사전.zip] |
| | | | |
| − | ==REST API== | + | == REST API == |
| − | ===기본 구조===
| |
| − | *REST API 형식
| |
| − | :*http://node201.hadoop.com:9200/index/type/id
| |
| − | :*http://node201.hadoop.com:9200/[index/][type/]action
| |
| − | :*curl -X<REST Verb> <Node>:<Port>/<Index>/<Type>/<ID>
| |
| − | ::*curl 'node201.hadoop.com:9200/index/type/id'
| |
| − | ::*curl 'node201.hadoop.com:9200/[index/][type/]action'
| |
| − | :*index, type, id를 여러개 지정할 경우 ","를 사용하여 구분. * 사용 가능
| |
| − | :*공통 parameter
| |
| − | ::*pretty : 반환 값이 있다면 JSON response를 표시
| |
| − | ::*v : verbose. 상세 정보 표시
| |
| − | ::*help : 사용 가능한 컬럼 정보 표시
| |
| − | ::*h=컬럼1,컬럼2 : headers. 컬럼 표시
| |
| − | ::*bytes=b : 1kb 대신에 1024와 같이 숫자를 표시
| |
| | | | |
| − | *curl REST Verb (curl -X???) | + | * |
| − | {|cellspacing="0" cellpadding="2" border="1" width="100%" bgcolor="#FFFFFF" align="center"
| + | === [[ElasticSearch - REST API|ElasticSearch - REST API]] === |
| − | |-
| |
| − | |width="20%" align="center" valign="middle" style="background-color:#eee;"|등록<br/>(POST, PUT)
| |
| − | |width="80%"|
| |
| − | *customer 인덱스 생성
| |
| − | curl -XPUT 'node201.hadoop.com:9200/customer?pretty'
| |
| − | curl -GET 'node201.hadoop.com:9200/_cat/indices?v'
| |
| − | | |
| − | *external 타입으로 문서 추가
| |
| − | :*문서 번호는 자동으로 생성
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/external?pretty' -d '
| |
| − | {
| |
| − | "name": "Mountain Lover"
| |
| − | }'
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/external/1lz2jL6CQui07FnZGd_R9w?pretty'
| |
| − | | |
| − | *external 타입으로 1번 문서 추가
| |
| − | curl -XPUT 'node201.hadoop.com:9200/customer/external/1?pretty' -d '
| |
| − | {
| |
| − | "name": "Mountain Lover"
| |
| − | }'
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/external/1?pretty'
| |
| − | |-
| |
| − | |align="center" valign="middle" style="background-color:#eee;"|수정<br/>(POST, PUT)
| |
| − | |
| |
| − | *external 타입으로 1번 문서 수정
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/external/1/_update?pretty' -d '
| |
| − | {
| |
| − | "doc": { "name": "Mountain Lover!", "age": 20 }
| |
| − | }'
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/external/1?pretty'
| |
| − | | |
| − | *external 타입으로 1번 문서 수정
| |
| − | curl -XPUT 'node201.hadoop.com:9200/customer/external/1?pretty' -d '
| |
| − | {
| |
| − | "name": "Mountain Lover!"
| |
| − | }'
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/external/1?pretty'
| |
| − | |-
| |
| − | |align="center" valign="middle" style="background-color:#eee;"|삭제<br/>(DELETE)
| |
| − | |
| |
| − | *문서 삭제
| |
| − | curl -XDELETE 'node201.hadoop.com:9200/customer/external/1?pretty'
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/external/1?pretty'
| |
| − |
| |
| − | curl -XDELETE 'node201.hadoop.com:9200/customer/external/_query?pretty' -d '
| |
| − | {
| |
| − | "query": { "match": { "name": "Mountain Lover!" } }
| |
| − | }'
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/external/1?pretty'
| |
| − | | |
| − | *customer 인덱스 삭제
| |
| − | curl -XDELETE 'node201.hadoop.com:9200/customer?pretty'
| |
| − | curl -GET 'node201.hadoop.com:9200/_cat/indices?v'
| |
| − | |-
| |
| − | |align="center" valign="middle" style="background-color:#eee;"|조회<br/>(GET)
| |
| − | |
| |
| − | *조회
| |
| − | curl -GET 'node201.hadoop.com:9200/_cat/indices?v'
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/external/1?pretty'
| |
| − | | |
| − | *조회되는 데이터 구조
| |
| − | :*_index
| |
| − | :*_type
| |
| − | :*_id
| |
| − | :*_version : 1, 2, 3, ...
| |
| − | :*_source : { name1: value1, name2: value2 }
| |
| − | |-
| |
| − | |align="center" valign="middle" style="background-color:#eee;"|검색<br/>(GET, POST)
| |
| − | |
| |
| − | *REST request URI
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/_search?q=*&pretty'
| |
| − | | |
| − | *REST request body
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/_search?pretty' -d '
| |
| − | {
| |
| − | "query": { "match_all": {} }
| |
| − | }'
| |
| − | |}
| |
| − | | |
| − | ===Document API===
| |
| − | *index api : -XPUT : 등록, -XPOST : 등록 (id 자동 생성)
| |
| − | :*/_create
| |
| − | ::*?op_type=create : 이미 데이터가 있으면 오류
| |
| − | :*?routing=~ : routing에 지정한 값의 해쉬값을 사용하여 작업할 node 지정
| |
| − | | |
| − | :*?version=n
| |
| − | :*?parent=~
| |
| − | :*?timestamp=2014-11-15T14%3A12%3A12
| |
| − | :*?ttl=34 : time to live (milliseconds)
| |
| − | :*?consistency=one, quorum, all
| |
| − | :*?replication=async, sync
| |
| − | :*?refresh=true
| |
| − | :*?timeout=5m
| |
| − | | |
| − | *get api : -XGET
| |
| − | :*?fields=~,~
| |
| − | :*?routing=~ : routing에 지정한 값의 해쉬값을 사용하여 작업할 node 지정
| |
| − | | |
| − | :*?version=n
| |
| − | :*?realtime=false
| |
| − | :*/_source : _source 필드만 반환 (-XHEAD 사용 가능)
| |
| − | :*?_source=false : _source 필드를 반환하지 않음
| |
| − | ::*?_source_include, _source_exclude
| |
| − | :*?preference=_primary, _local, ~
| |
| − | :*?refresh=true
| |
| − | | |
| − | *delete api : -XDELETE
| |
| − | :*?routing=~ : routing에 지정한 값의 해쉬값을 사용하여 작업할 node 지정
| |
| − | | |
| − | :*?version=n
| |
| − | :*?parent=~
| |
| − | :*?consistency=one, quorum, all
| |
| − | :*?replication=async, sync
| |
| − | :*?refresh=true
| |
| − | :*?timeout=5m
| |
| − | | |
| − | *update api : -XPUT
| |
| − | :*/_update
| |
| − | :*"script" 필드 사용법
| |
| − | ::*ctx._source.필드명
| |
| − | "script" : "ctx._source.counter += count",
| |
| − | "params" : { #--- script에 인자 전달
| |
| − | "count" : 4
| |
| − | }
| |
| − |
| |
| − | ctx._source.remove(\"text\") #--- 필드 삭제
| |
| − | ctx._source.tags.contains(tag) ? (ctx.op = \"delete\") : (ctx.op = \"none\")
| |
| − | if (ctx._source.tags.contains(tag)) { ctx.op = \"none\" } else { ctx._source.tags += tag }
| |
| − | :*"upsert" : 필드가 있으면 수정, 없으면 등록
| |
| − | :*"doc_as_upsert": true : 문서가 있으면 수정, 없으면 등록
| |
| − | :*?routing=~ : routing에 지정한 값의 해쉬값을 사용하여 작업할 node 지정
| |
| − | :*?parent=~
| |
| − | :*?replication=async, sync
| |
| − | :*?timeout=5m
| |
| − | :*?consistency=one, quorum, all
| |
| − | :*?refresh=true
| |
| − | :*?fields=~,~
| |
| − | :*?version=n
| |
| − | :*?version_type
| |
| − | :*?timestamp=2014-11-15T14%3A12%3A12
| |
| − | ::*ctx._timestamp
| |
| − | :*?ttl=34 : time to live (milliseconds)
| |
| − | ::*ctx._ttl
| |
| − | | |
| − | *multi get api : -XGET, /_mget
| |
| − | curl -XGET 'node201.hadoop.com:9200/_mget' -d '{
| |
| − | "docs": [
| |
| − | {
| |
| − | "_index": "~",
| |
| − | "_type": "~",
| |
| − | "_id": "~"
| |
| − | }
| |
| − | }
| |
| − | }'
| |
| − |
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/external/_mget' -d '{
| |
| − | "ids": ["~", "~"]
| |
| − | }'
| |
| − | :*"_source"
| |
| − | "_source": false
| |
| − | "_source": [ "field1", "field2" ]
| |
| − | "_source": {
| |
| − | "include": [ "~" ],
| |
| − | "exclude": [ "~", "~" ]
| |
| − | }
| |
| − | :*"fields": [ "~", "~" ]
| |
| − | :*"_routing": "~"
| |
| − | | |
| − | *bulk api : /_bulk
| |
| − | :*requests 파일
| |
| − | #--- index, create, update, delete
| |
| − | { "index": { "_index": "~", "_type": "~", "_id": "~" } }
| |
| − | { "field1": "value1" }
| |
| − | { "update": { "_index": "~", "_type": "~", "_id": "~" } }
| |
| − | { "doc": { "field1": "value1" }, "doc_as_upsert": true }
| |
| − | #--- upsert, doc_as_upsert, script, params, lang 파라메터 지원
| |
| − | :*bulk api
| |
| − | curl -s -XPOST 'node201.hadoop.com:9200/_bulk --data-binary @requests
| |
| − | :*_version, _routing, _parent, _timestamp, _ttl, _consistency
| |
| − | :*?refresh=true
| |
| − | | |
| − | *delete by query api : -XDELETE, /_query
| |
| − | curl -XDELETE 'node201.hadoop.com:9200/customer/external/_query?q=user:~'
| |
| − | #--- q : query
| |
| − | #--- df : default field
| |
| − | #--- analyzer : query analyzer
| |
| − | #--- default_operator : OR (default), AND
| |
| − |
| |
| − | curl -XDELETE 'node201.hadoop.com:9200/customer/external/_query' -d '{
| |
| − | "query": {
| |
| − | "term": { "user": "~" }
| |
| − | }
| |
| − | '}
| |
| − | :*?routing=~ : routing에 지정한 값의 해쉬값을 사용하여 작업할 node 지정
| |
| − | :*?replication=async, sync
| |
| − | :*?consistency=one, quorum, all
| |
| − | | |
| − | *bulk udp api
| |
| − | :*설정
| |
| − | bulk.udp.enabled: true
| |
| − | bulk.udp.bulk_actions: 1000
| |
| − | bulk.udp.bulk_size: 5m #-- 5MB
| |
| − | bulk.udp.flush_interval: 5s
| |
| − | bulk.udp.concurrent_requests: 4
| |
| − | bulk.udp.host: #--- network.host에 지정된 값이 default임
| |
| − | bulk.udp.port; 9700-9800
| |
| − | bulk.udp.receive_buffer_size: 10mb
| |
| − | :*사용법
| |
| − | cat requests | nc -w 0 -u node201.hadoop.com 9700
| |
| − | | |
| − | *term vectors api
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/external/1/_termvector?pretty=true&fields=~,~"
| |
| − | | |
| − | *multi termvectors api
| |
| − | curl -XGET 'node201.hadoop.com:9200/_mtermvectors' -d '{
| |
| − | "docs": [
| |
| − | {
| |
| − | "_index": "~",
| |
| − | "_type": "~",
| |
| − | "_id": "~",
| |
| − | "term_statistics": true
| |
| − | }
| |
| − | ]
| |
| − | '}
| |
| − | | |
| − | ===Search API===
| |
| − | *http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/_the_search_api.html
| |
| − | *http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/query-dsl.html
| |
| − | | |
| − | *REST request uri search
| |
| − | :*q : [http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html Query String Query]
| |
| − | :*analyzer
| |
| − | :*default_operator : OR (default), AND
| |
| − | :*_source = false, _source_include, _source_exclude
| |
| − | :*df : 디폴트 필드 지정
| |
| − | :*fields : 필드 지정
| |
| − | :*sort : field:asc, field:desc
| |
| − | :*explain
| |
| − | :*track_score = true
| |
| − | :*timeout
| |
| − | :*from : 반환할 레코드의 시작 인덱스 (0, 1, 2, ...)
| |
| − | :*size : 반환할 레코드 수 (디폴트는 10)
| |
| − | :*search_type : query_then_fetch (default), dfs_query_the_fetch, dfs_query_and_fetch, query_and_fetch, count, scan
| |
| − | :*lowercase_expanded_terms
| |
| − | :*analyze_wildcard : false (default), true
| |
| − | :*scroll=5m
| |
| − | :*preference : _primary, _primary_first, _local, _only_node:xyz, _prefer_node:xyz, _shards:2,3
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/_search?q=*&pretty'
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/_search?pretty&q=user:kimchi'
| |
| − | | |
| − | *REST request body search
| |
| − | :*_all : 모든 인덱스를 가르키는 예약어
| |
| − | :*?routing=~ : routing에 지정한 값의 해쉬값을 사용하여 작업할 node 지정
| |
| − | | |
| − | :*"from" : 0
| |
| − | :*"size" : 10
| |
| − | :*"sort" : [ { "post_date" : {"order" : "asc"}}, "_score" ]
| |
| − | :*"_source": false
| |
| − | :*"_source": { "include": [ "obj1.*", "obj2.*" ], "exclude": [ "*.description" ] }
| |
| − | :*"fields" : ["user", "postDate"]
| |
| − | :*"script_fields" : 계산을 통하여 새로운 필드 생성
| |
| − | :*"fielddata_fields" : ["test1", "test2"]
| |
| − | :*"post_filter" : { "term" : { "tag" : "green" } }
| |
| − | :*"highlight" : 결과에 highlight 추가
| |
| − | :*"rescore" : _score 계산 규칙 조정
| |
| − | :*"explain": true
| |
| − | :*"version": true
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/_search?pretty' -d '
| |
| − | {
| |
| − | "query": { "match_all": {} },
| |
| − | "sort": { "balance": { "order": "desc" } }, #--- 정렬
| |
| − | "from": 10, #--- 10번째까지 skip
| |
| − | "size": 10, #--- 10개의 데이터 반환
| |
| − | "_source": [ "account_number", "balance" ] #--- 반환할 필드 지정
| |
| − | }'
| |
| − | | |
| − | *query
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/_search?pretty' -d '
| |
| − | {
| |
| − | "query": {
| |
| − | "term": { "user": "kimchi" }
| |
| − | }
| |
| − | }'
| |
| − | | |
| − | *match_all query
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/_search?pretty' -d '
| |
| − | {
| |
| − | "query": { "match_all": {} }
| |
| − | }'
| |
| − | | |
| − | *match query
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/_search?pretty' -d '
| |
| − | {
| |
| − | "query": { "match": { "account_number": 20 } }
| |
| − | }'
| |
| − | | |
| − | *match_phrase query
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/_search?pretty' -d '
| |
| − | {
| |
| − | "query": { "match_phrase": { "address": "mill lane" } }
| |
| − | }'
| |
| − | | |
| − | *bool query
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/_search?pretty' -d '
| |
| − | {
| |
| − | "query": {
| |
| − | "bool": {
| |
| − | #--- "must" : AND, "should" : OR, "must_not" : NOT (~ AND ~)
| |
| − | "must": [
| |
| − | { "match": { "address": "mill" } },
| |
| − | { "match": { "address": "lane" } }
| |
| − | ],
| |
| − | "must_not": [
| |
| − | { "match": { "state": "ID" } }
| |
| − | ]
| |
| − | }
| |
| − | }
| |
| − | }'
| |
| − | | |
| − | *filtered query
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/_search?pretty' -d '
| |
| − | {
| |
| − | "query": {
| |
| − | "filtered": {
| |
| − | "query": { "match_all": {} },
| |
| − | "filter": {
| |
| − | "range": { #--- range filter
| |
| − | "balance": {
| |
| − | "gte": 20000,
| |
| − | "lte": 30000
| |
| − | }
| |
| − | }
| |
| − | }
| |
| − | }
| |
| − | }
| |
| − | }'
| |
| − | | |
| − | *aggregation
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/_search?pretty' -d '
| |
| − | {
| |
| − | "size": 0,
| |
| − | "aggs": {
| |
| − | "group_by_state": { #--- count(state) 반환
| |
| − | "terms": {
| |
| − | "field": "state"
| |
| − | }
| |
| − | }
| |
| − | }
| |
| − | }'
| |
| − |
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/_search?pretty' -d '
| |
| − | {
| |
| − | "size": 0,
| |
| − | "aggs": {
| |
| − | "group_by_state": { #--- state별 avg(balance) 반환
| |
| − | "terms": {
| |
| − | "field": "state",
| |
| − | "order": {
| |
| − | "average_balance": "desc"
| |
| − | }
| |
| − | },
| |
| − | "aggs": {
| |
| − | "average_balance": {
| |
| − | "avg": {
| |
| − | "field": "balance"
| |
| − | }
| |
| − | }
| |
| − | }
| |
| − | }
| |
| − | }
| |
| − | }'
| |
| − | | |
| − | *search shards api : search 문이 어떤 노드의 shards에서 처리되었는지 정보 반환
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/_search_shards'
| |
| − | | |
| − | *search template : Template를 사용하여 search문 구성
| |
| − | curl -XGET 'node201.hadoop.com:9200/customer/_search/template?pretty' -d '{
| |
| − | "template" : {
| |
| − | "query": { "match" : { "{{my_field}}" : "{{my_value}}" } },
| |
| − | "size" : "{{my_size}}"
| |
| − | },
| |
| − | "params" : {
| |
| − | "my_field" : "foo",
| |
| − | "my_value" : "bar",
| |
| − | "my_size" : 5
| |
| − | }
| |
| − | }'
| |
| − | | |
| − | ====facets====
| |
| − | *search에 결과에 대한 aggregation 처리나 통계 처리
| |
| − | :*terms : 필드에 대한 통계 처리
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/_search?pretty=true' -d '{
| |
| − | "query" : { ~ },
| |
| − | "facets": { "terms": { "field": "~" } }
| |
| − | }'
| |
| − | | |
| − | *facets global 설정
| |
| − | :*main : 현재 search문에만 적용
| |
| − | :*global : 모든 search문에 적용
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/_search?pretty=true' -d '{
| |
| − | "facets": {
| |
| − | "myFacets": {
| |
| − | "terms": { "field": "~" },
| |
| − | "global": true
| |
| − | }
| |
| − | }
| |
| − | }'
| |
| − | | |
| − | *facet filter
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/_search?pretty=true' -d '{
| |
| − | "facets": {
| |
| − | "myFacets": {
| |
| − | "terms": { "field": "~" }
| |
| − | },
| |
| − | "facet_filter" {
| |
| − | "terms": { "user": "kimchi" }
| |
| − | }
| |
| − | }
| |
| − | }'
| |
| − | | |
| − | *terms facet : 빈도수가 높은 10개의 terms을 반환
| |
| − | :*"all_terms" : true
| |
| − | :*"exclude" : ["term1", "term2"]
| |
| − | :*"regex" : "_regex expression here_", "regex_flags" : "DOTALL"
| |
| − | :*"script" : "term + 'aaa'"
| |
| − | :*"script" : "term == 'aaa' ? true : false"
| |
| − | :*"script_field" : "_source.my_field",
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/_search?pretty=true' -d '{
| |
| − | "query" : { ~ },
| |
| − | "facets": {
| |
| − | "필드": {
| |
| − | "terms": {
| |
| − | "field": "~",
| |
| − | "size": 10,
| |
| − | "order": "count" #--- count (default), term, reverse_count, reverse_term
| |
| − | }
| |
| − | }
| |
| − | }
| |
| − | }'
| |
| − | | |
| − | ===APIs===
| |
| − | {|cellspacing="0" cellpadding="2" border="1" width="100%" bgcolor="#FFFFFF" align="center"
| |
| − | |-
| |
| − | |width="20%" align="center" valign="middle" style="background-color:#eee;"|API
| |
| − | |width="80%" align="center" valign="middle" style="background-color:#eee;"|상세 | |
| − | |-
| |
| − | |align="center" valign="middle"|_cat API
| |
| − | |
| |
| − | *http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/cat.html
| |
| − | | |
| − | *Cluster health check : http://node201.hadoop.com:9200/_cat/health?v
| |
| − | *Node information : http://node201.hadoop.com:9200/_cat/nodes?v
| |
| − | | |
| − | *Index information : http://node201.hadoop.com:9200/_cat/indices?v
| |
| − | :*http://node201.hadoop.com:9200/_cat/indices/인덱스명?v
| |
| − | *Master information : http://node201.hadoop.com:9200/_cat/master?v
| |
| − | *Shards information : http://node201.hadoop.com:9200/_cat/shards?v
| |
| − | :*http://node201.hadoop.com:9200/_cat/shards/샤드명?v
| |
| − | *Alias information : http://node201.hadoop.com:9200/_cat/aliases?v
| |
| − | | |
| − | *Distk 할당 정보 : http://node201.hadoop.com:9200/_cat/allocation?v
| |
| − | *전체 문서 개수 : http://node201.hadoop.com:9200/_cat/count?v
| |
| − | :*인덱스의 문서 개수 : http://node201.hadoop.com:9200/_cat/count/인덱스명?v
| |
| − | | |
| − | *Node별 로드된 필드 데이터 정보 : http://node201.hadoop.com:9200/_cat/fielddata?v
| |
| − | *http://node201.hadoop.com:9200/_cat/fielddata/필드1,필드2?v
| |
| − | *http://node201.hadoop.com:9200/_cat/fielddata?v&fields=필드1,필드2
| |
| − | | |
| − | *Pending tasks information : http://node201.hadoop.com:9200/_cat/pending_tasks?v
| |
| − | *Plugin information : http://node201.hadoop.com:9200/_cat/plugins?v
| |
| − | *Recovery information : http://node201.hadoop.com:9200/_cat/recovery?v
| |
| − | *Thread pool information : http://node201.hadoop.com:9200/_cat/thread_pool?v
| |
| − | |-
| |
| − | |align="center" valign="middle"|_nodes API
| |
| − | |
| |
| − | *http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/cluster.html
| |
| − | *Node명 지정 방법
| |
| − | :*_nodes/_local : 로컬 node
| |
| − | :*_nodes/IP1,IP2
| |
| − | :*_nodes/노드명
| |
| − | :*_nodes/노드속성
| |
| − | |-
| |
| − | |align="center" valign="middle"|_cluster API
| |
| − | |
| |
| − | *http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/cluster-health.html
| |
| − | | |
| − | *Cluster health check : http://node201.hadoop.com:9200/_cluster/health?pretty=true
| |
| − | :*http://node201.hadoop.com:9200/_cluster/health/인덱스1,인덱스2?pretty=true
| |
| − | |-
| |
| − | |align="center" valign="middle"|
| |
| − | |
| |
| − | |-
| |
| − | |align="center" valign="middle"|
| |
| − | |
| |
| − | |-
| |
| − | |align="center" valign="middle"|
| |
| − | |
| |
| − | |-
| |
| − | |align="center" valign="middle"|
| |
| − | |
| |
| − | |-
| |
| − | |align="center" valign="middle"|
| |
| − | |
| |
| − | |-
| |
| − | |align="center" valign="middle"|
| |
| − | |
| |
| − | |-
| |
| − | |align="center" valign="middle"|
| |
| − | |
| |
| − | |-
| |
| − | |align="center" valign="middle"|
| |
| − | |
| |
| − | |}
| |
| − | | |
| − | *참고 문헌
| |
| − | :*[http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/query-dsl.html Query DSL]
| |
| − | :*http://www.querydsl.com/
| |
| − | | |
| − | ===Basic API===
| |
| − | *Node
| |
| − | curl -X GET http://node201.hadoop.com:9200/_status #--- 상태 확인
| |
| − | | |
| − | *Index 관리 (데이터베이스)
| |
| − | :*_all : 모든 index 적용
| |
| − | curl -X POST http://node201.hadoop.com:9200/index001 #--- index 생성
| |
| − | curl -X DELETE http://node201.hadoop.com:9200/index001 #--- index 삭제
| |
| − |
| |
| − | curl -X GET http://node201.hadoop.com:9200/index001/_mapping #--- Mapping 조회
| |
| − | curl -X GET http://node201.hadoop.com:9200/index001/_status #--- 상태 확인
| |
| − | curl -X GET http://node201.hadoop.com:9200/index001/_search #--- 검색
| |
| − | curl -X GET http://node201.hadoop.com:9200/_all/_search #--- 검색
| |
| − | | |
| − | *Type 관리 (테이블)
| |
| − | #--- type 생성, _id는 자동으로 생성됨
| |
| − | curl -X POST http://node201.hadoop.com:9200/index001/type001 -d '{ title: "Greeting", body: "Hello World!" }'
| |
| − | curl -X DELETE http://node201.hadoop.com:9200/index001/type001 #--- type 삭제
| |
| − |
| |
| − | curl -X GET http://node201.hadoop.com:9200/index001/type001/_mapping #--- Mapping 조회
| |
| − | curl -X GET http://node201.hadoop.com:9200/index001/type001/_status #--- 상태 확인
| |
| − | curl -X GET http://node201.hadoop.com:9200/index001/type001/_search #--- 검색
| |
| − | http://node201.hadoop.com:9200/index001/type001/_search?q=title:Gre*ting
| |
| − | | |
| − | *Mapping 관리 (테이블 스키마)
| |
| − | #--- Mapping 생성
| |
| − | curl -X PUT http://node201.hadoop.com:9200/index001/type001/_mapping -d '{
| |
| − | type001: {
| |
| − | properties: {
| |
| − | title: {
| |
| − | type: "string",
| |
| − | index: "not_analyzed"
| |
| − | }
| |
| − | }
| |
| − | }
| |
| − | }'
| |
| − | curl -X GET http://node201.hadoop.com:9200/index001/type001/_mapping #--- Mapping 조회
| |
| − | | |
| − | *Document 관리 (레코드)
| |
| − | #--- document 생성
| |
| − | curl -X POST http://node201.hadoop.com:9200/index001/type001/data001 -d '{ title: "Greeting", body: "Hello World!" }'
| |
| − | curl -X POST http://node201.hadoop.com:9200/index001/type001/data001/_update -d '{ title: "Greeting", body: "Hello World!" }'
| |
| − | curl -X DELETE http://node201.hadoop.com:9200/index001/type001/data001 #--- data001 데이터 삭제
| |
| − |
| |
| − | curl -X GET http://node201.hadoop.com:9200/index001/type001/data001 #--- data001 데이터 조회
| |
| − | #--- document 검색
| |
| − | curl -X GET http://node201.hadoop.com:9200/index001/type001/_search -d '{query: {text: {_all: "Hello"}}}'
| |
| − | | |
| − | *Search
| |
| − | :*q : 검색어, fieldName:fieldValue
| |
| − | :*default_operator=OR : 기본 연산자, AND, OR
| |
| − | :*fields=_source : 반환할 필드
| |
| − | :*sort : 정렬, field:asc, field:desc
| |
| − | :*timeout : 검색 수행 타임아웃, default는 무제한
| |
| − | :*size=10 : 반환할 데이터의 개수
| |
| − | http://node201.hadoop.com:9200/index001/type001/_search?q=title:Gre*ting
| |
| − | curl -X POST http://node201.hadoop.com:9200/index001/type001/_search -d '{ query: {term: {title: "Greeting"}} }'
| |
| − | curl -X POST http://node201.hadoop.com:9200/index001/type001/_search -d '{ query: {bool: {must: {match: {title: "Greeting"}}}} }'
| |
| − | | |
| − | *Prefix query
| |
| − | :*scoring_boolean
| |
| − | :*constant_score_boolean : score를 계산하지 않음
| |
| − | :*constant_score_filter : filter를 사용
| |
| − | :*top_terms_n : scoring_boolean과 유사하나 n개의 결과만 반환
| |
| − | :*top_terms_boost_n : top_terms_n과 유사하지만 boost에 대해서 score 계산
| |
| − | curl -X GET 'http://node201.hadoop.com:9200/index001/type001/_search?pretty' -d '{
| |
| − | "query": {
| |
| − | "prefix": {
| |
| − | "name": "j", #--- j로 시작하는 단어 검색
| |
| − | "rewrite": "constant_score_boolean"
| |
| − | }
| |
| − | }
| |
| − | }'
| |
| − | | |
| − | *Rescore
| |
| − | {
| |
| − | "fields" : ["title", "available"],
| |
| − |
| |
| − | "query" : {
| |
| − | "match_all" : {}
| |
| − | },
| |
| − |
| |
| − | "rescore" : {
| |
| − | "query" : {
| |
| − | "rescore_query" : {
| |
| − | "custom_score" : {
| |
| − | "query" : {
| |
| − | "match_all" : {}
| |
| − | },
| |
| − | "script" : "doc['year'].value"
| |
| − | }
| |
| − | }
| |
| − | }
| |
| − | }
| |
| − | }
| |
| − | :*window_size
| |
| − | :*query_weight
| |
| − | :*rescore_query_weight
| |
| − | :*rescore_mode = total , max , min , avg , and multiply
| |
| − | ::*total : original_query_score * query_weight + rescore_query_score * rescore_query_weight
| |
| − | | |
| − | ===Bulk API=== | |
| − | *Bulk로 문서 등록, 수정, 삭제
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/external/_bulk?pretty' -d '
| |
| − | {"index":{"_id":"1"}}
| |
| − | {"name": "John Doe" }
| |
| − | {"index":{"_id":"2"}}
| |
| − | {"name": "Jane Doe" }
| |
| − | '
| |
| − |
| |
| − | curl -XPOST 'node201.hadoop.com:9200/customer/external/_bulk?pretty' -d '
| |
| − | {"update":{"_id":"1"}}
| |
| − | {"doc": { "name": "John Doe becomes Jane Doe" } }
| |
| − | {"delete":{"_id":"2"}}
| |
| − | '
| |
| − | | |
| − | *documents.json 파일을 사용하여 Bulk indexing
| |
| − | curl -XPOST http://node201.hadoop.com:9200/customer/external/_bulk?pretty --data-binary @documents.json
| |
| − | | |
| − | *Multi Get
| |
| − | curl http://node201.hadoop.com:9200/library/book/_mget?fields=title -d '{
| |
| − | "ids" : [1,3]
| |
| − | }'
| |
| − | | |
| − | *MultiSearch
| |
| − | curl http://node201.hadoop.com:9200/library/books/_msearch?pretty --data-binary '
| |
| − | { "type" : "book" }
| |
| − | { "filter" : { "term" : { "year" : 1936} }}
| |
| − | { "search_type": "count" }
| |
| − | { "query" : { "match_all" : {} }}
| |
| − | { "index" : "library-backup", "type" : "book" }
| |
| − | { "sort" : ["year"] }
| |
| − | '
| |
| − | *Sort
| |
| − | {
| |
| − | "query" : {
| |
| − | "terms" : {
| |
| − | "title" : [ "crime", "front", "punishment" ],
| |
| − | "minimum_match" : 1
| |
| − | }
| |
| − | },
| |
| − | "sort" : [
| |
| − | { "section" : "desc" }
| |
| − | #-- {"release_dates" : { "order" : "asc", "mode" : "min" }}
| |
| − | #-- min, max, avg, sum
| |
| − | ]
| |
| − | }
| |
| − | | |
| − | ===Indexing data===
| |
| − | *REST API
| |
| − | :*[heep://curl.haxx.se curl]을 사용하여 테스트 가능
| |
| − | curl -XPUT http://localhost:9200/blog/article/1 -d '{~}'
| |
| − | *bulk API
| |
| − | *UDP bulk API
| |
| − | *river plugin
| |
| − | | |
| − | ===User Query DSL===
| |
| − | *[[Lucene#Lucene_Query_language|Lucene Query language]]
| |
| − | | |
| − | *TF/IDF (Term Frequency / Inverse Document Frequency)
| |
| − | :*Document boost
| |
| − | :*Field boost
| |
| − | :*Coord
| |
| − | :*Inverse document frequency
| |
| − | :*Length norm
| |
| − | :*Term frequency
| |
| − | :*Query norm
| |
| − | | |
| − | [[파일:LuceneScore01.png|700px]]
| |
| − | [[파일:LuceneScore02.png|700px]]
| |
| − | :*q : Query
| |
| − | :*d : Document
| |
| − | | |
| − | *Query type
| |
| − | :*custom_boost_factor
| |
| − | :*constant_score
| |
| − | :*custom_score
| |
| | | | |
| | ==JAVA API== | | ==JAVA API== |
Lucene을 바탕으로 개발한 분산 검색엔진인 ElasticSearch를 정리 합니다.
ElasticSearch 개요
Lucene은 널리 알려진 Java 기반의 오픈소스 검색 엔진 라이브러리 입니다. 많은 곳에서 사용 되고 있지만 라이브러리 형태라 사용에 불편함이 있고 BigData 시대를 맞아 분산 환경을 지원하지 않아 새로운 대안 솔루션이 필요하게 되었습니다. 오픈소스 진영에서는 분산 환경을 지원하는 Solr와 ElasticSearch가 Lucene 기반으로 작성이 되었습니다. ElasticSearch는 RESTful API를 지원하는 특성으로 인하여 여러 환경으로 포팅이 될 수 있어서 사용이 편리한 분산 검색 엔진 입니다.
ElasticSearch의 특징
- 실시간 검색 및 분석
- 분산 구성 및 병렬 처리
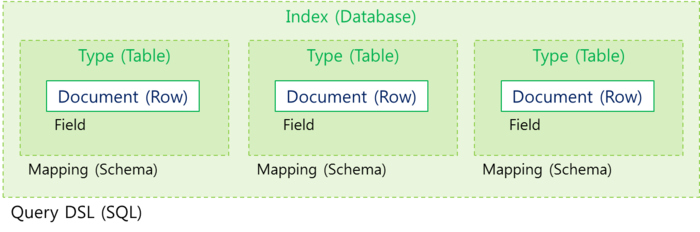
- index (Database)와 Type (Table)을 사용하여 다양한 문서 처리
- JSON을 사용하는 RESTful API 지원
- Plugin 방식의 기능 확장
ElasticSearch 용어
| 용어
|
상세
|
| Cluster
|
|
| Node
|
|
|
Index
(indice)
|
- 유사한 특징을 가진 문서들의 모음으로 DBMS에서 데이터베이스와 유사한 개념
- Term, Count, Docs로 구성
|
| Shard
|
- Index의 subset 개념으로 Lucene을 사용하여 구성
- 실제 데이터와 색인을 저장하고 있으며 Primary Shard와 Replica Shard로 분류
- Primary Shard : Shard를 구성하는 기본 인덱스
- Replica Shard : 분산된 다른 node에 저장된 Primary Shard의 복제본
|
Type
(Document Type)
|
- 데이터 (Document)의 종류로 index 내에서의 논리적인 category/partition
- DBMS에서 테이블과 유사한 개념
|
| Mapping
|
|
| Route
|
- 색인 필드 중 unique key에 해당하는 값을 routing path로 지정한 후, 이 path를 사용하여 인덱싱과 검색에 사용할 shard를 지정하여 성능할 향상할 수 있습니다.
- Routing Field : 스토어 옵션을 yes로 index not_analyzed로 설정
|
| Document
|
- ElasticSearch에서 관리하는 기본적인 데이터(정보)의 저장 단위
- JSON (JavaScript Object Notaion)으로 표현
- DBMS에서 레코드와 유사한 개념
|
| Field
|
- Document를 구성하고 있는 항목으로 name과 value로 구성
- DBMS에서 컬럼과 유사한 개념
|
| Gateway
|
- Cluster 상태, Index 설정 등의 정보를 저장
|
| Query
|
|
| TermQuery
|
|
| Term
|
|
| Token
|
|
ElasticSearch의 개념적 구성도
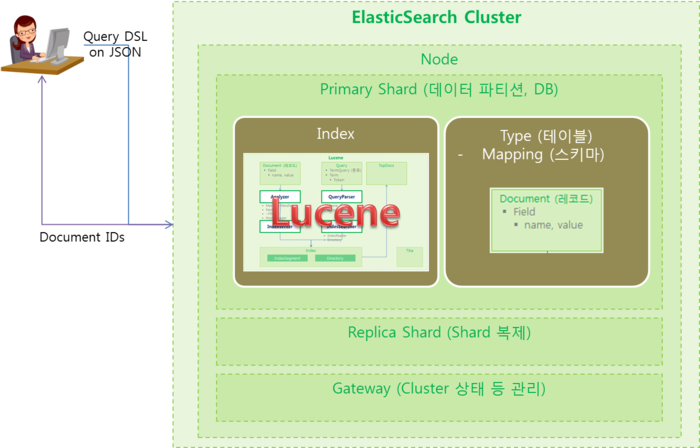
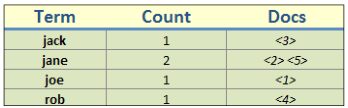
- ElasticSearch Architecture
- _index : index 이름
- _type : type 이름
- _id : Document ID
- _score
- _source : Document 저장
- properties
-
ElasticSearch 관련 오픈소스
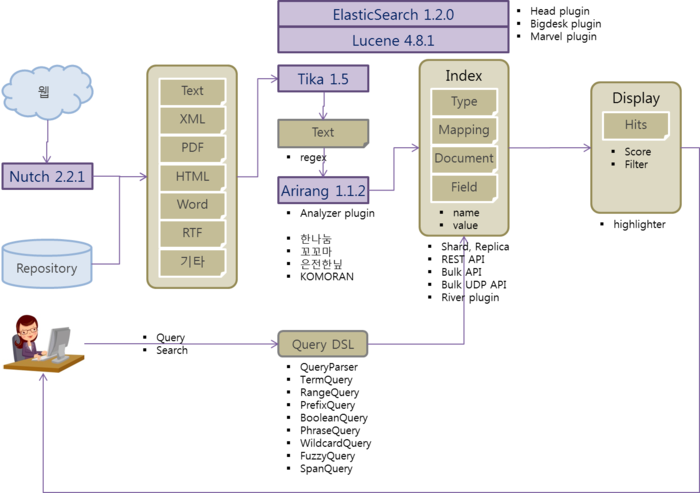
CentOS에서 ElasticSearch 설치
ElasticSearch 설치
cd install
wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.3.2.tar.gz
tar -xvzf elasticsearch-1.3.2.tar.gz
chown -R hduser:hdgroup elasticsearch-1.3.2
mv elasticsearch-1.3.2 /nas/appl/elasticsearch
### ----------------------------------------------------------------------------
### ELASTICSEARCH 설정
### ----------------------------------------------------------------------------
export ELASTICSEARCH_HOME=/nas/appl/elasticsearch
export PATH=$PATH:$ELASTICSEARCH_HOME/bin
cd /nas/appl/elasticsearch
mkdir data
mkdir logs
chown hduser:hdgroup data logs
- vi /nas/appl/elasticsearch/config/elasticsearch.yml
cluster.name: elasticsearch
node.name: "node201"
path.data: /nas/appl/elasticsearch/data
path.logs: /nas/appl/elasticsearch/logs
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.unicast.hosts: ["node201:9200"]
bootstrap.mlockall: true
su - hduser
elasticsearch #--- Foreground로 실행
elasticsearch -d #--- Daemon으로 실행
curl localhost:9200 #--- 서비스 확인
http://node201.hadoop.com:9200/ #--- 서비스 확인
http://node201.hadoop.com:9200/_status
http://node201.hadoop.com:9200/_plugin/head/ #--- elasticsearch-head plugin이 설치된 경우
ElasticSearch 로드밸런서 설치
- ElasticSearch 로드밸런서 환경 설정
- vi /nas/appl/elasticsearch/config/elasticsearch.yml
node.master: false
node.data: false
network.bind_host: 192.168.0.1
plugin -install mobz/elasticsearch-head
plugin -install lukas-vlcek/bigdesk
환경 설정
- bin/elasticsearch 환경변수
- JAVA_OPTS
- ES_JAVA_OPTS, ES_HEAP_SIZE
- ES_MIN_MEM=256m, ES_MAX_MEM=1gb
vi /nas/appl/elasticsearch/config/elasticsearch.yml
index:
store:
type: memory
elasticsearch -Des.index.store.type=memory
curl -XPUT 'node201.hadoop.com:9200/customer/ -d '
index:
store:
type: memory
'
curl 'node201.hadoop.com:9200/_nodes/process?pretty'
- memory settings : disable swap
swapoff -a
vi /etc/fstab
#--- swap을 주석 처리
ulimit -l unlimited #--- root 사용자로 실행
mkdir /tmp/tmpJna
vi config/elasticsearch.yml
bootstrap.mlockall: true
elasticsearch -Djna.tmpdir=/tmp/tmpJna
Service로 실행
- ES_USER, ES_GROUP
- ES_HEAP_SIZE, ES_HEAP_NEWSIZE, ES_DIRECT_SIZE
- MAX_OPEN_FILES
- MAX_LOCKED_MEMORY, MAX_MAP_COUNT
- LOG_DIR, DATA_DIR, WORK_DIR
- CONF_DIR, CONF_FILE
- ES_JAVA_OPTS, RESTART_ON_UPGRADE
#--- /etc/init.d/elasticsearch
#--- /etc/sysconfig/elasticsearch
/sbin/chkconfig --add elasticsearch
Windows에서 ElasticSearch 설치
ElasticSearch 설치
ElasticSearch는 JDK 7 이상에서 실행되는 Java 기반의 애플리케이션으로 별도의 설치 과정 없이 소스를 다운로드 받아 실행하면 됩니다. 다운로드 사이트(http://www.elasticsearch.org/download/)에서 최신 버전(elasticsearch-1.3.2.zip)의 ElasticeSearch를 다운로드 합니다. 압축을 풀어 c:/appl/elasticsearch/ 폴더를 생성 합니다.
실행 및 확인
bin/ 폴더에서 elasticsearch.bat 파일을 실행 합니다.
브라우저에서 http://localhost:9200/ 로 접속하여 확인 합니다.

Cluster 정보 확인
Node 정보 확인
Plugin 설치
한글 형태소 분석기 Plugin
Korean Analysis for ElasticSearch (http://github.com/chanil1218/elasticsearch-analysis-korean) 사이트에서 한글 형태소 분석기 Plugin을 설치 합니다. ElasticSearch용 한글 형태소 분석기 Plugin은 "루씬 한글분석기 오픈소스 프로젝트"를 가져와 작성이 되었습니다.
루씬 한글분석기 오픈소스 프로젝트
한글 형태소 분석기 Plugin 설치
설치가 정상적으로 완료되면 plugins/analysis-korean/elasticsearch-analysis-korean-1.3.0.jar 파일을 확인할 수 있습니다.
-
curl -XDELETE 'node201.hadoop.com:9200/korea?pretty'
#curl -XDELETE 'node201.hadoop.com:9200/korea?pretty'
curl -XPUT 'node201.hadoop.com:9200/korea?pretty' -d '{
"settings": {
"index": {
"analysis": {
"analyzer": {
"kr_analyzer": {
"type": "org.elasticsearch.index.analysis.KoreanAnalyzerProvider",
"tokenizer": "KoreanTokenizer",
"filter": [ "trim", "lowercase", "KoreanFilter" ]
}
}
}
}
}
}'
### curl -XGET 'node201.hadoop.com:9200/korea/_analyze?pretty&analyzer=kr_analyzer&text=이전 글에서 ElasticSearch와 Arirang 형태소 분석기를 살펴 보았습니다.'
curl -XGET 'node201.hadoop.com:9200/korea/_analyze?pretty&analyzer=kr_analyzer&text=%EC%9D%B4%EC%A0%84%20%EA%B8%80%EC%97%90%EC%84%9C%20ElasticSearch%EC%99%80%20Arirang%20%ED%98%95%ED%83%9C%EC%86%8C%20%EB%B6%84%EC%84%9D%EA%B8%B0%EB%A5%BC%20%EC%82%B4%ED%8E%B4%20%EB%B3%B4%EC%95%98%EC%8A%B5%EB%8B%88%EB%8B%A4.'
http://node201.hadoop.com:9200/korea/_analyze?pretty&analyzer=kr_analyzer&text=이전%20글에서%20ElasticSearch와%20Arirang%20형태소%20분석기를%20살펴%20보았습니다.
- elasticsearch-analysis-korean-1.3.0.jar 파일 구조
plugin=org.elasticsearch.plugin.analysis.kr.AnalysisKoreanPlugin
org.apache.lucene.analysis.kr
dic/
KoreanAnalyzer.java
KoreanFilter.java
KoreanTokenizer.java
org.apache.solr.analysis.kr
KoreanFilterFactory.java
KoreanTokenizerFactory
org.elasticsearch.index.analysis
KoreanAnalysisBinderProcessor.java
KoreanAnalyzerProvider.java
KoreanFilterFactory.java
KoreanTokenizerFactory.java
org.elasticsearch.plugin.analysis.kr
AnalysisKoreanPlugin.java
- AnalysisKoreanPlugin.java : AnalysisModule로 KoreanAnalysisBinderProcessor 등록
- KoreanAnalysisBinderProcessor.java : Analyzer, Tokenizer, Filter 등록
- KoreanAnalyzerProvider.java (kr_analyzer) -> KoreanAnalyzer
- KoreanTokenizerFactory.java (kr_tokenizer) -> KoreanTokenizer
- KoreanFilterFactory.java (kr_filter) -> KoreanFilter
ElasticSarch 폴더 구조
| 폴더
|
설정 변수
|
상세
|
| bin
|
|
윈도우용 실행 파일
- elasticsearch.bat : ElasticSearch 실행
- service.bat : Service 형태로 ElasticSearch 실행
service.bat install | remove | start | stop | manager [SERVICE_ID]
- plugin.bat : Plugin Manager 실행
Linux용 실행 파일
- elasticsearch : ElasticSearch 실행
- plugin : Plugin Manager 실행
|
| config
|
path.conf
|
설정 파일 폴더
- elasticsearch.yml : ElasticSearch 설정 파일
- logging.yml : 로그 설정 파일
|
| data
|
path.data
|
데이터와 인덱스를 저장하는 폴더
- path.data: /path/to/data1,/path/to/data2
|
| lib
|
|
ElasticSearch용 라이브러리
- Lucene 검색 엔진 라이브러리
- Sigar 라이브러리 : CPU, Memory, Disk 등을 모니터링
|
| logs
|
path.logs
|
로그 폴더
|
| plugins
|
path.plugins
|
ElasticSearch 플러그인 폴더
|
| work
|
path.work
|
임시 작업용 폴더
|
- path.home : ElasticSearch가 설치된 폴더를 지정하는 설정 변수
ElasticSearch 구성
YAML 문법에 따라 elasticsearch.yml 파일에서 설정 변수를 구성 합니다.
| 설정 변수
|
Default
|
상세
|
| cluster.name
|
elasticsearch
|
Cluster 이름
data/Cluster 이름/ 폴더가 생성됨
|
| node.name
|
0, 1, 2, ...
(자동 생성)
|
Node 이름
data/Cluster 이름/nodes/Node 이름/ 폴더가 생성됨
|
|
node.master
node.data
node.client
|
true
true
false
|
Node 종류
- Master node
- node.master: true
- Cluster와 Node의 상태 정보를 관리
- Index와 Shard의 조정자 역할
- Data node
- node.data: true
- 색인 데이터를 저장
- Load Balance node
- node.master: false, node.data: false
- 검색 요청을 받아 분산 처리
- Client node
- node.client: true, node.master: false
- Master node로 사용하지 않고 Client node로 사용하고자 할 경우
|
index.number_of_shards
|
5
|
Shard 개수
|
index.number_of_replicas
|
1
|
Replica 개수
|
http.enabled
|
true
|
http 서비스를 활성화 합니다.
|
http.port
|
9200
|
http 서비스에서 사용하는 port
|
transport.tcp.port
|
9300
|
netty의 Transport에서 사용하는 port
|
transport.tcp.compress
|
|
true이면 Transport에서 압축 허용
|
network.bind_host
|
|
Client의 요청을 접수할 IP 주소
|
network.host
|
|
ElasticSearch Node의 IP 주소
|
gateway.type
|
local
|
Cluster의 메타 정보와 Index 설정, Mapping 정보 등을 어디서 관리할 것인지 지정
Gateway 종류
- local
- shared fs
- hadoop
- s3
|
discovery.zen.minimum_master_nodes
|
1
|
최소 Master node 개수 (2개 이상 권장)
|
discovery.zen.ping.timeout
|
3s
|
|
discovery.zen.ping.multicast.enabled
|
true
|
|
discovery.zen.ping.unicast.hosts
|
|
Unicast 사용시 검색할 서버와 포트
예) ["host1", "host2:port"]
|
Java 개발 환경 구성
ElasticSearch Java 환경 구성
- lib/elasticsearch-1.2.1.jar
- src/main/java/ 폴더 아래의 소스 파일을 사용 합니다.
Lucene Java 환경 구성
- Lucene 사이트에서 "DOWNLOAD" 버튼을 눌러 lucene-4.8.1.zip 파일을 다운로드 합니다.
- core/lucene-core-4.8.1.jar
- Lucene 사이트에서 "DOWNLOAD" 버튼을 눌러 lucene-4.8.1-src.tgz 파일을 다운로드 합니다.
- core/src/java/ 폴더 아래의 소스 파일을 사용 합니다.
Arirang Java 환경 구성
- arirang.morph 소스를 먼저 받아 mvn install 진행
파일:Arirang 사전.zip http://www.jopenbusiness.com/mediawiki/images/5/54/Arirang_사전.zip
REST API
JAVA API
Client
import static org.elasticsearch.node.NodeBuilder.nodeBuilder;
import org.elasticsearch.client.Client;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.ImmutableSettings;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.node.Node;
private Boolean getTransportClient() {
Settings settings = null;
settings = ImmutableSettings.settingsBuilder().put("cluster.name", CLUSTER_NAME).build();
client = new TransportClient(settings).addTransportAddress(new InetSocketTransportAddress(HOST, PORT));
return true;
}
//--- elasticsearch.yml
//--- cluster.name=~
private Boolean getNodeClient() {
node = nodeBuilder().clusterName(CLUSTER_NAME).client(true).local(true).node();
client = node.client();
return true;
}
index java api
import static org.elasticsearch.common.xcontent.XContentFactory.jsonBuilder;
import org.elasticsearch.action.index.IndexResponse;
json = jsonBuilder().startObject()
.field("name", "value")
.endObject().string();
res = client.prepareIndex("index", "type", "id").setSource(json).execute().actionGet();
UtilLogger.info.print(logCaller, "_index : " + res.getIndex());
UtilLogger.info.print(logCaller, "_type : " + res.getType());
UtilLogger.info.print(logCaller, "_id : " + res.getId());
UtilLogger.info.print(logCaller, "_version : " + res.getVersion());
UtilLogger.info.print(logCaller, "_index : " + res.getIndex());
get java api
관리자 매뉴얼
elasticsearch.yml
- index.query.bool.max_clause_count
오류 처리
- vi /nas/appl/elasticsearch/bin/elasticsearch.in.sh
#ES_MIN_MEM=256m
#ES_MAX_MEM=1g
ES_MIN_MEM=4g
ES_MAX_MEM=4g
- 많은 Client에서 접속하여, 파일 개수 부족으로 오류 발생시
org.elasticsearch.common.netty.channel.ChannelException: Failed to create a selector.
Caused by: java.io.IOException: Too many open files
ulimit -n
vi /etc/security/limits.conf
hduser soft nofile 999999
hduser hard nofile 999999
참고 문헌
-



