BigData 방법론
둘러보기로 가기
검색하러 가기
BigData 방법론을 정리 합니다.
BigData 구축 방법론

BigData 분석 조직
- BigData 분석 조직
조직 산출물 상세 기획 및 설계 - 빅데이터 분석 및 활용 가치 기획
- 빅데이터 분석을 위한 플랫폼 설계
플랫폼 엔지니어 - 하둡 등 분산저장 시스템 구출
- 빅데이터 플랫폼 모니터링 및 기술지원
응용 개발/운영 - 분산 저장 및 병렬 처리 플랫폼 활용 개발
- 기간 시스템 연계 및 데이터 수집, 저장, 관리
개발분석가 - 분산 저장 환경하에서 빅데이터 병렬 처리
- MapReduce, Pig, Hive 등 하둡 생태계 도구 활용
분석/시각화 - 전처리 데이터를 대상으로 통계 분석
- 오픈소스 R 등 시각화 도구 활용
- 참고 문헌 : 빅데이터 활용가치 및 국내외 적용 사례
- 데이터 검열사 (Data Hygienist) : 데이터에 대한 안전성 판단
- 데이터 조사원 (Data Explorer) : 필요 데이터 필터링
- 비즈니스 솔루션 설계사 (Business Solution Architecture) : 데이터 통합/체계화
- 데이터 과학자 (Data Scientist) : 분석 모델 제시
- 캠페인 전문가 (Campaign Expert) : 분석 자료로 결과 도출, 마케팅 캠페인에 대한 지식 필요
BigData 분석 방법론
Data Mining Process Standards
CRISP-DM
- CRISP-DM (Cross-Industry Standard Process for Data Mining)
- Reference Model : Phases -> Generic Tasks -> Specialized Tasks -> Process Instances (Actions)
- User Guide : check lists, questionaires, tools and techniques, sequences of steps, decion points, pitfalls
단계 상세 비즈니스 이해
(Business Understanding)- 목표
- 고객의 요구 사항과 비즈니스 목표를 이해하고 이를 데이터 마이닝의 목표로 전환
- 결과에 영향을 주는 중요한 항목을 도출하고 마이닝 목표를 달성하기 위한 예비 계획 수립
- Actions
- Determine Business Objects : 비즈니스 관점에서 고객 요구를 이해
- Assess Situation : 프로젝트에 영향을 미치는 요인에 대한 사실 조사
- Determine Data Mining Goals : 기술적인 측면에서 프로젝트 목표를 결정
- Produce Project Plan : 프로젝트의 목표를 달성하기 위한 세부 계획의 준비
- 기업내의 어떤 문제점을 빅데이터로 해결할 것인가?
데이터 이해
(Data Understanding)- 목표
- 초기 데이터를 수집, 이해하고 데이터의 품질을 정의하고 몇가지 가설을 구성하기 위한 데이터셋을 설정
- Actions
- Collect Initial Data : 초기 데이터를 수집
- Describe Data : 수집된 데이터의 특성을 확인
- Explore Data : 질의, 시각화, 보고서 등 데이터 마이닝 목표에 부합하는 데이터 추출
- Verify Data Quality : 데이터의 품질 검사
- 문제 해결을 위해 어떤 데이터를 사용하여야 하는가?
- 문제 해결을 위한 데이터 이면에 숨겨져 있는 원리는?
- 변수 선정
데이터 준비
(Data Preparation)- 목표
- 모델링 도구의 입력이 될 최종 데이터를 원시 데이터로부터 추출
- Actions
- Select Data : 분석에 사용할 데이터를 선별
- Clean Data : 분석 기법에서 요구한 수준으로 데이터의 품질을 향상
- Construct Data : 분석을 위한 구조화된 데이터 준비
- Integrate Data : 분석을 위해 여러 테이블에서 데이터를 통합
- Format Data : 사용하려는 모델에 적합하도록 데이터의 구문 수정
- KDD : 데이터 -> (추출) 목표 데이터 -> (전처리) 사전처리 데이터
- Process 2 : 데이터 입력 -> 데이터 확인
모형
(Modeling)- 목표
- 모델링 기법을 선택하고 최적의 값을 가진 파라메터 변수를 설정
- Actions
- Select Modeling Technique : 모델링 기법 선택
- Generate Test Design : 모델의 유효성을 검사하고 품질을 테스트하는 절차 생성
- Build Model : 모델을 구축하는 모델링 기법을 실행
- Assess Model : 해석, 평가, 비교 및 데이터 마이닝 관점에서 평가 기준에 따라 모델의 순위 지정
- KDD : (변환) 변환 데이터 -> (데이터 마이닝) 패턴
- Process 2 : 모델링 (데이터 처리 및 분석)
평가
(Evaluation)- 목표
- 충분한 평가를 통해서 비즈니스 목표를 달성할 것으로 확신되는 모델을 선정
- 전체 프로세스를 재검토하고 다음 단계를 결정
- Actions
- Evaluate Results : 결과가 비즈니스 목표에 부합하는지 확인
- Review Process : 빠트린 사항이 없도록 중요 항목을 도출하고 전체 프로세스를 요약
- Determine Next Steps : 다음 단계를 결정
- KDD : (해석/평가) 지식
- Process 2 : 검증
- 수리적 모델의 검증과 변수/데이터의 확인
적용
(Deployment)- 목표
- 프로세스를 통해서 획득한 지식을 가공하여 고객에게 제시
- Actions
- Plan Deployment : 비즈니스에 프로젝트의 결과를 반영하기 위한 전략 수립
- Plan Monitoring and Maintenance : 유지 보수 전략의 준비
- Produce Final Report : 프로젝트의 최종 보고서 작성
- Review Project : 최종 보고서 검토
- Process 2 : 정리 및 시각화

SEMMA
- SEMMA (Simple, Explore, Modify, Model, Assess)
- Sample : Input data, Sampling, Data partition
- Explore : Distributeion explorer, Multiplot, Insight, Association, Variable selection
- Modify : Transform variable, Filter outliers, Clustering, SOM / Kohonen
- Model : Regression, Tree, Neural Network, Ensemble
- Assess : Assessment, Score, Report
- http://timkienthuc.blogspot.kr/2012/04/crm-and-data-mining-day-08.html

단계 상세 Sampling - 분석 데이터 생성
- 통계적 추출
- 조건 추출
- 비용 절감 및 모델 평가를 위한 데이터 준비
Explore - 분석 데이터 탐색
- 기초 통계, 그래픽적 탐색
- 요인별 분할표
- Clustering
- 변수 유의성 및 상관분석
- 데이터 조감을 통한 데이터 오류 검색
- 모델의 효율 증대
- 데이터 현황을 통해 비즈니스 이해, 아이디어를 위해 이상현상, 변화 등을 탐색
Modify - 분석 데이터 수정/변환
- 수량화, 표준화, 각종 변환, 그룹화
- 데이터가 지닌 정보의 표현 극대화
- 최적의 모델을 구축할 수 있도록 다양한 형태로 변수를 생성, 선택, 변형
Modeling - 모델 구축
- Neural Network
- Decision Tree
- Logistic Regression
- 전통적 통계
- 데이터의 숨겨진 패턴 발견
- 하나의 비즈니스 문제 해결을 위해 특수의 모델과 알고리즘 적용 가능
Assessment - 모델 평가 및 검증
- 텍스트 교본
- Feedback
- 모델의 검증
- 서로 다른 모델을 동시에 비교
- 추가 분석 수행 여부 결정
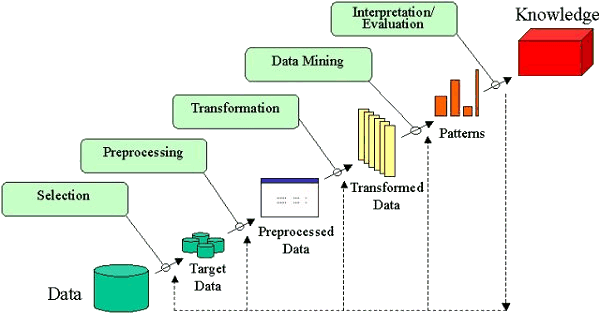
KDD
- KDD (Knowledge Discovery in Databases)
BigData 분석 기법
빅데이터 분석 단계(수준)
- 데이터 이해 -> 데이터 분석 -> 고급 분석
- 데이터 분석
- 정형 보고서 : 무슨일이 발생 하였는가?
- 비정형 보고서 : 얼마나 많이, 자주, 어디에서 발생 하였는가?
- OLAP : 검색/드릴다운, 문제의 원인은 어디에 있는가?
- 경보 : 어떠한 행동이 필요한가?
- 고급 분석
- 기술 분석 (Descriptive Analytics)
- 통계 분석 : 이 결과가 나타난 이유는?
- 예측 분석 (Predictive Analytics)
- 시계열 예측 : 이 추세가 계속되면 어떻게 될 것인가?
- 예측 모델링 : 다음에 발생할 일은 무엇인가?
- 최적화 (Optimization)
- 최적화 : 발생할 일에 대한 가장 최선의 대안은 무엇인가?
- 고급 분석 (Advanced Analytics) : 비즈니스 상황을 예측하고 효율적인 의사결정을 지원하기 위해 구조화 및 비구조화된 복잡한 형태의 데이터에서 요인들간의 상관관계와 의미있는 데이터의 패턴을 식별하고 예측하기 위한 모든 기법과 기술
- 기술 분석 (Descriptive Analytics) : 과거에서부터 현재까지 주어진 데이터로부터 현재의 상황을 설명할 수 있는 Pattern을 찾아 사용자의 이해를 돕기 위해 표현하거나 설명 - 상관 분석, 군집, 분류, ...
- 예측 분석 (Predictive Analytics) : 과거의 데이터나 사건으로부터 미래에 발생 가능한 상황이나 사건을 예측하여 선제적인 의사결정을 지원
- 최적화 (Optimization) : 주어진 가능한 결과들에 대한 평가를 수행하여 최적의 결과를 도출하는 것
- Content Analysis, Text Analytics, Realtime Analytics
BigData 분석 모형
- BigData 분석 모형
모델 기법 알고리즘 Classification
(분류)과거의 데이터를 입력으로하여 분류 모델을 생성하고, 새로운 데이터에 대하여 분류값을 예측
- Decision Tree
- Memory-Based Reasoning
- Bayesian Classification
- CART
- CHAID
- C4.5
- k-nearest neighbor
- Naive Bayes
Clustering
(군집)데이터의 여러 속성(변수)를 고려하여 성질이 비슷한 몇개의 집합으로 구분
- Partition Based
- Hierarchical Based
- Navigation Sequencing
- k-means
- k-medoids
- Expectation Maximization
- BIRCH
- CURE
- Markov Chain
Association
(연관)- Market Basket Analysis
- Sequence Discovery
- Link Analysis
- Association Rules
- Exponential Smoothing
- Box-Jenkins
- Directed Graphs
Estimation
(예측)- Regression (회귀분석)
- Neural Network
- Linear Regression
- Robust Regression
- Logistic
- Supervised Learning
- Backward Propagation
- Feed Forward
- Genetic Algorithm
Description
(기술)- Exploratory Data Analysis
- Dimensionality Reduction
- Histograms
- Box-and-Whisker
- Parento
- Principal Components-Factor Analysis
Text - Information Retrieval or Identification of a Corpus
- Natural Language Processing
- Named Entity Recognition
- Recognition of Pattern Identified Entities
- Coreference
- Relationship, Fact and Event Extraction
- Sentiment Analysis
- Quantitative Text Analysis
- 일반적으로 모델링 준비에서 개발 완료까지 1개를 개발하는데 초급. 2MM, 중급. 1MM, 고급. 0.5MM
BigData 분석 기법
- Data Mining/Analytic 기법
- Decision Trees/Rules (62.6%)
- Regression (51.2%)
- Clustering (50.2%) : Classification, Clustering
- Statistics (descriptive) (46.3%)
- Visualization (32.5%)
- Association rules (26.1%) : Association Analysis
- Sequence/Time series analysis (17.2%) : Sequential patterns
- Neural Nets (17.2%)
- SVM (15.8%)
- Bayesian (15.8%)
- Boosting (14.8%)
- Nearest Neighbor (12.8%)
- Hybrid methods (11.8%)
- Other (11.3%)
- Genetic algorithms (11.3%)
- Bagging (10.8%)
- Forecasting
- Text Mining
- Social Network Analysis
통계 (Statistics) 분석
- 빈도 분석
- 각 변수 값에 속한 분포의 특성을 찾아내는 분석 기법
- 도수분포표, 집중경향치 (Central Tendency), 분산도 (Dispersion), 히스토그램
- 기술통계 분석
- 자료의 필요 통계량을 간단히 산출하는 분석 방법, 요약 통계량과 Z-Score 계산
- 평균, 표준편차, 최소값, 최대값, 빈도수, 분산, 범위, 평균 오차, 왜도, 첨도
- 교차 분석
- 범주형 변수인 명목/서열 자료 변수간 상관 관계인 독립성과 연관성 분석
- 신뢰도 분석
- 동일 개념을 독립 측정 방법에 의한 측정 결과가 비슷한지의 일관성의 측정
- 설문지의 신뢰성 측정과 요인 분석시 추출인자의 신뢰성 측정
- 상관관계 분석
- 분석 대상 변수간의 관련 정도, 관계의 방향, 상관계수에 대한 가설의 검증
- 회귀 분석
- 종속 변수와 독립 변수의 관련성의 강도 파악
- 독립 변수 값의 변화에 따른 종속 변수 값의 변화를 예측하는데 사용
- T-검증
- 독립된 두 집단간의 평균의 차이가 통계적으로 유의한지를 검증
- 분산 분석
- 두 집단 이상의 평균 차이를 검증하는데 사용, 일원 분산 분석과 다원 분산 분석
- 다변량 분석
- 종속 변수가 2개 이상시 종속 변수간 평균값의 차이 검증
- 독립변수가 어떤 종속 변수에 더 많은 영향을 미치는 지 파악
- 판별 분석
- 독립 변수의 역할 관계를 바탕으로 종속 변수(집단 구분)를 추정하는 통계 기법
- 집단 판별의 선형 판별 함수 생성과 집단 구분에 영향을 미치는 변수 발견
- 요인 분석
- 변수들 상호간의 상호 의존도를 분석하여 서로 유사한 변수들 끼리 묶어주는 방법
- 군집 분석
- 대상 속성들의 유사한 성향을 바탕으로 동질적인 집단으로 묶어 동일 집단내에 속하는 공통 특성을 발견
기타 분석
- 빅데이터 분석 역량
- 쿼리와 리포팅
- 데이터 마이닝
- 데이터 시각화
- 예측 모델링
- 최적화
- 시뮬레이션
- 자연 언어 텍스트
- 지리공간적 분석
- 스트리밍 분석
- 비디오 분석
- 음성 분석
- 주요 용어 정리
용어 상세 시계열 분석 예측 분석
(Predictive Analytics)데이터 마이닝
(Data Mining)- 데이터 마이닝 (Data Mining) : 대규모 정형화된 데이터로부터 가치있는 정보를 추출하는 것
- 30~1000+ 개의 변수를 분석하여 유의미한 변수가 무엇인지 어떤 규칙이 있는지, 미래에 어떻게 될지의 정보를 얻고자 하는것
- 통계학, 기계 학습, 인공 지능, 컴퓨터 과학 등과 결합하여 사용
- 로지스틱 회귀분석 (Logistic Regression), 주성분분석 (Principal Analytis), 판별분석 (Discriminant Analysis), 군집분석 (Clustering Analysis), 분류(Classfication), 예측(Forecasting), 연관분석(Association Analysis) 등
- KDD (Knowledge Discovery in Databases) : 데이터 -> (추출) 목표 데이터 -> (전처리) 사전처리 데이터 -> (변환) 변환 데이터 -> (데이터 마이닝) 패턴 -> (해석/평가) 지식
- 데이터 마이닝 표준 처리 과장 (CRISP-DM, Cross Industry Standard Process for Data Mining)
- 비즈니스 이해 (Business Understanding) -> 데이터 이해 (Data Understanding) -> 데이터 준비 (Data Preparation) -> 모형 (Modeling) -> 평가 (Evaluation) -> 적용 (Deployment)
- 한국 BI 데이터마이닝학회
- 통계청 : 통계 정보국의 빅데이터 연구회
텍스트 마이닝
(Text Mining)- 비정형 데이터의 마이닝 : Text Mining, Web Mining 등
- 비정형 데이터 : 그림이나 문서 처럼 형태와 구조가 정형화 되어 있지 않은 데이터
- 문서 분류 (Document Classification), 문서 군집 (Document Clustering), 메타데이터 추출 (Metadata Extraction), 정보 추출 (Information Extration) 등
- 정보 검색, 컴퓨터 언어학, 데이터 마이닝, 통계학, 기계 학습 등
- 웹 마이닝 (Web Mining) : 웹 페이지 또는 웹 로그 데이터로부터 가치있는 정보를 추출하는 데이터 마이닝
- Web Structure Mining, Web Usage Mining, Web Contents Mining
- 오피니언 마이닝 (Opinion Mining, 평판 분석) : 어떤 사안이나 인물, 이슈, 이벤트에 대한 사람들의 의견이나 평가, 태도, 감정 등을 분석
자연어처리
(NLP)- 자연어 처리 (NLP, Natural Language Processing) : 인간의 언어를 컴퓨터가 인색하여 처리
- 형태소 분석, 구분 분석, 개체명 인식 등
정보 검색
(IR)- 색인 기술
- 시스템이 정보 검색의 수요자
정보 수집
(Crawling)- Web Craw, Spiders, Worm, Robots, Bots
기계 학습
(Machine Learning)- 인공 지능
- 충분한 학습 데이터로부터 모델을 생성하고, 해당 모델을 통해 대용량 데이터를 자동 분석, 귀납 추론하는 시스템
- 통상 SVMrhk 같은 통계 이론에 기반하며, 자동 분류, 자동 군집, 베이지안 네트워크 기반 추론 등 강력한 데이터 분석 기능을 제공
Cloud, NoSQL Semantic - 데이터의 의미적 분석
- 시맨틱 메타데이터 자동 추출, 시맨틱 네트워크 생성, 지식 베이스 구축, 온톨로지의 활용, 논리 및 통계적 추론 등
시각화
(Visualization)- 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달하는 과정
- 통계그래픽 (Statistical Graphics), 주제도 지도학 (Thematic Cartography)
SNS Analytics - 그래프 이론을 기반으로 소셜네트워크의 연결구조, 강도 등을 분석 (명성, 영향력 등 측정)

- BigData Analytics
- Analytics
- 예측 분석 (Predictive Analytics)
- 컨텍스트 분석 (Context Analytics)
- 실시간 분석 (Real-Time Analytics)
- 고급 분석 (Advanced Analytics)
- 감성 분석 (Sentimental Analytics)
- 소셜 분석 (Social Analytics)
- Models
- Explanatory Models
- 예측 Models
- 의사결정 Models
- Methods
- Segmentation & Clustring
- 분류
- Decision trees
- Logistic regression
- Neural networks
- 예측
- Time Series
- Regression
- Charts : Gain Chart, Lift Chart, K-S Chart
- Statistics : Confusion Matrix, Mean Square Error, Variables Contribution
- MPP (Massively Parallel Processing)
- SMP (Symmetric Multi-Processing)
BigData 수집 방법론
수집 개요
- 빅데이터의 종류
빅데이터 종류 상세 거래 데이터 P2M
기업 내부 데이터- 상거래 (아마존의 구매 리스트), 제품 사용 (구글의 검색 기록)
로그 데이터 M2M - 보안 분야에 활용
- 소비나 서비스 이용 로그에 기반한 개인화된 마케팅
- 카드사 : 구매정보를 분석해서 실험하는 빅데이터 마케팅, 스마트폰앱
이벤트 - 클릭 정보
이메일 소셜미디어 P2P 소비자 관련 통계 금융 과학 센서 외부 데이터 RFID, POS 자유 형식 텍스트 위치 정보 오디오 정지화상/비디오
- BigData 소스
구분 상세 내부 데이터 - 트랜잭션 : 88%
- 로그 : 73%
- 이메일 : 57%
외부 데이터 - 소셜 미디어 : 43%
- 오디오 : 38%
- 사진/동영상 : 34%
전체 데이터 - 웹로그 (51%)
- 클릭 정보 (35%)
- 상거래, 제품 사용 (30% 대)
- 소비자 관련 통계, 소셜 미디어, 금융 (20% 대)
- 과학 데이터, 센서 데이터 (10% 대)
- 빅데이터 분석 Platform 규모 : 1TB ~ 10TB
- 참고 문헌
- 문서 내용 검색
- CentOS
yum install poppler-utils or xpdf-utils pdftotext pdfFile textFile
- DOC (upt to MS Word 2004)
yum install catdoc
- DOCX (MS Word 2007+)
wget http://silvercoders.com/index.php?page=DocToText make build/doctotext
- 참고 문헌
- 검색 로봇
- Open API
수집 방법론
- BigData 수집 방법론
- 데이터 정의 -> [ 수집 -> 정형화 -> 중복 제거 ] -> 저장
- Event 정의 -> EPL -> Output Adapter -> Input Adapter
단계 산출물 상세 데이터 정의 - Data Checkpoint : Volume, Quality, Relevance, Variety, Timeliness
- 비정형 데이터 -> 텍스트 마이닝, 소셜네트워크 분석, 기계 학습
- 웹, SNS, 음성, 문서
- 정형 테이터 -> 수치 분석, 데이터 마이닝
- 클리스트림, M2M (센서, GPS)
수집 정형화 중복 제거 저장
수집 도구
- 로그 수집 도구
수집 도구 상세 syslog - 커널이나 각종 데몬, 애플리케이션 등이 출력하는 로그를 취득해, 미리 유저가 지정한 방법으로 파일에 기록하거나 특정의 서버에 송신하는 프로그램
Snort - 침입탐지시스템
- Signature, Destination IP
NetFlow - 네트워크 트래픽 분석
- Destination Port, Octets
SIM/SEM
- 로그 종류별 상세
소스 병합 필드 상세 방화벽 Sensor IP, Time, Source IP, Destination IP, Destination Port, Protocol, Direction, Action
침입탐지시스템 Sensor IP, Time, Source IP, Destination IP, Destination Port, Protocol, Direction, Signature
웹 Sensor IP, Time, Source IP, Destination IP, Destination Port, Protocol, Method, URL, Result Code
데이터 소스
데이터 포맷
상관 분석 유형
시각화 템플릿 유형
ADP 시험
ADP 실기 시험 문제
- 1회 : http://www.jopenbusiness.com/wordpress/?p=338
- 2회 : https://docs.google.com/presentation/d/1nfjNz95C3Xb6BFjXQyWktNWXAcZqpYzOn-DDQIXW4JA/edit?usp=sharing
참고 문헌
- 로그
- 분석