BigData
둘러보기로 가기
검색하러 가기
BigData를 정리 합니다.
목차
BigData 개요
빅데이터의 정의
- 기존 데이터에 비해 너무 방대해 일반적으로 사용하는 방법이나 도구로 수집, 저장, 처리, 분석, 시각화 등을 하기 어려운 정형 또는 비정형 데이터의 집합
| 초점 | 정의 |
| 데이터 규모 (맥킨지, 2011.5) |
기존 데이터베이스 관리 도구의 데이터 수집, 저장, 관리, 분석하는 역량을 넘어서는 데이터 |
| 업무 수행 방식 (IDC, 2011.6) |
다양한 종류의 대규모 데이터로부터 저렴한 비용으로 가치를 추출하고, 데이터의 빠른 수집, 발굴, 분석을 지원하도록 고안된 차세대 기술 및 아키텍처 |
빅데이터의 3대 요소(3V)
BigData는 크기(Volume)가 크고 변화(Velocity)의 속도가 빠르며 데이터의 속성이 다양(Variety)한 데이터를 입니다. BigData의 핵심 기술은 대규모 저장 시스템과 효과적인 데이터 처리 기술 입니다. 3대 요소 가운데 두가지 이상의 요소만 충족하면 빅데이터라고 볼 수 있습니다. 비즈니스 측면에서는 3V에 Value를 추가하여 4V를 사용 합니다.
| Volume (데이터의 규모) |
|
| Variety (데이터의 다양성) |
|
| Velocity (데이터의 속도) |
|
| Value (데이터의 가치) |
|

BigData 관련 표준화 동향
- ISO/IEC JTC 1/SC32 : 데이터 관리 및 교환 (데이터 표현)
- ISO/IEC JTC 1/SC23 : 정보 교환 및 저장 (데이터 압축 및 저장)
- ISO/IEC JTC 1/SC27 : 보안
- ISO/IEC JTC 1/SC29 WG11 (MPEG) : 정규화 및 자연어 처리
- ISO/IEC JTC 1/SC7 (ISO/IEC 25012) : 소스트웨어와 시스템 공학 기술
- ITU-T SG13 : 클라우드 기반의 빅데이터 분석
- ITU-T SG16 : 멀티미디어 빅데이터
- ITU-T SG17 : 사생활 보호
- W3C BigData CG : 빅데이터 처리를 위한 표준 구조, 프로그램 API
- ODCA (Open Data Center Alliance) : 데이터 수집/관리/분석 표준, BI와 상호 운영성 표준
- ODI (Open Data Institute) : 공공 데이터 공유 및 개방
빅데이터 증가 현황
- 2012년 생성된 디지털 정보량은 2.8ZB, 2년마다 2배씩 증가해 2020년 40ZB(IDC, 2011)
- 2010년 ~ 2015년 모바일 연평균 92%, 인터넷은 연평균 34% 트래픽 증가 (Cisco, 2011)
- SNS, Mobile, M2M의 급속한 성장
| SNS |
|
| Mobile |
|
| 디지털 정보량 |
|
| 데이터 생성 속도 |
|
- 국내 디지털 데이터량 (IDC & 한국EMC)
- 2006 : 2.891 페타바이트
- 2007 : 4,401 페타바이트
- 2008 : 7,218 페타바이트
- 2009 : 12,105 페타바이트
- 2010 : 18,415 페타바이트
- 2011 : 27,237 페타바이드 (27 엑사바이트) 예상 (연평균 56.6% 증가)
BigData 2.0 개요
빅데이터 1.0이 BigData를 수집하고 이해하고 이를 활용하는 단계라면 빅데이터 2.0은 기업의 의사결정 과정에 BigData를 적극적으로 통합하는 단계 입니다. 다시 말하면 비즈니스의 목표를 달성하기 위해서 적극적인 방식으로 BigData를 활동하는 단계 입니다.
- BigData 2.0의 3대 요소
| 고객의 행동을 형성 (Shaping customer behavior) |
|
| 새로운 제품이나 서비스의 생성 (Creation of new product or service) |
|
| 데이터 생태계 확장 (Ecosystem view of data) |
|
- 참고 문헌
BigData 업체
국내 BigData 업체
| 업체 | 제품 | 상세 |
| 넥스알 (NexR) |
NDAP |
|
| 그루터 (Gruter) |
클라우몬 씨날 |
|
| KTH | Daisy (데이지) |
|
| LG CNS | SBP |
|
| SK C&C | 스톰 |
|
| 사이람 | NetMiner, NetMetrica |
|
| 솔트룩스 (Saltlux) |
truestory, IN2, STORM, O2 |
|
| 클라우다인 | 플라밍고 |
|
| 빅데이터 솔루션 포럼 (BIGSF) |
싸이밸류 얼라이언스(Cyvalue Alliance) |
|
| 다음소프트 | SOCIALmetrics |
|
- BI포럼
- 빅데이터 포럼
- 빅데이터 국가 전략 포럼
- 삼성SDS : 삼성지놈닷컴 - 유전자 분석 서비스
- KT
- 유전자 분석 서비스인 게놈클라우드 제공
- UCloud Biz MapReduce : 빅데이터 분석 서비스
- SK텔레콤
- Smart Insight : 소셜 모니터링/분석 솔루션
- T-MR : 시범 서비스
- 참고 문헌
해외 BigData 업체
| 업체 | 제품 | 상세 |
| Hortonworks | HDP |
|
| Cloudera | CDH (Cloudera Hadoop) |
|
| MapR Tech | MapR |
|
| IBM | Big Insight, Stream |
|
| Oracle | 빅데이터 어플라이언스 |
|
| EMC | GreenplumHD Isilion, 아이모스 |
|
| SAP | HANA |
|
| Splunk | Splunk |
|
| SAS | SAS BigData Analytics Platform |
|
| HP | 버티카, 오토노미 |
|
| Dell |
| |
| 인텔 |
| |
| Teradata | 애스터 맵리듀스 플랫폼 |
|
| Microsoft |
|
BigData 서비스
| 업체 | 서비스 | 상세 |
| Amazon | Amazon Web Service |
|
| Google Cloud Platform |
| |
| MS | Microsoft Azure |
|
| KT | UCloud MapReduce |
|
BigData Platform
| 서비스 | ||
| 관리 | ||
| 분석 도구 | ||
| 프로세싱 |
|
|
| 인프라 |
|
- 데이터 수집
- 첨부 파일 데이터 수집
- PDF, MS Office, 한글 / 훈민정음
- 버전별 처리
- 문서별 양식지 사용시 처리 방안
- 수집 로봇 (웹 로봇)
- Open API를 사용하여 수집
- 검색 엔진
- 형태소 분석 등을 위해 사전이 필요, 사전이 검색 엔진의 정확도 결정
- 표준어 사전
- 사용자 사전 : 회사에서만 사용하는 특수한 용어
BigData 방법론
비즈니스 모델
시장 규모
세계 빅데이터 기술 및 서비스 2014-2018 (IDC, 2014.10)
- 2013년 165억 5천만 달러
- 2018년 415억 달러 (연평균 26.4% 성장)
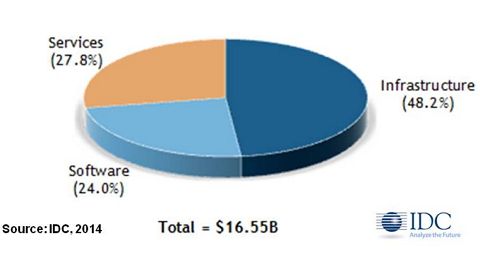
- IDC 2011, 단위 : 백만 달러
- 매년 약 40% 성장하여 2015년에는 169억 2000만 달러 규모로 성장
- S/W. 26%, 서비스.40%, 서버. 10%, 스토리지. 20%, 네트워킹. 4%
- 2011. 1.9 제타바이트, 5년 이내 9배 증가

| 구분 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | CAGR(%) |
| 서버 | 495 | 665 | 803 | 1,032 | 1,270 | 1,657 | 27.3 |
| 스토리지 | 318 | 560 | 1,224 | 1,968 | 2,719 | 3,429 | 61.4 |
| 네트워킹 | 106 | 146 | 242 | 368 | 485 | 620 | 42.4 |
| SW | 1,062 | 1,415 | 1,851 | 2,476 | 3,376 | 4,625 | 34.2 |
| 서비스 | 1,236 | 1,979 | 2,721 | 3,883 | 5,009 | 6,538 | 39.5 |
| 합계 | 3,217 | 4,766 | 6,842 | 9,728 | 12,941 | 16,920 | 39.4 |

- IDC : 비즈니스 분석 SW - 2016. 507억 달러 (연평균 9.8% 성장)
- BigData Market Forecaset (Wikibon, 2012)
- 2012 : 51억 달러
- 2013 : 102억 달러
- 2014 : 168억 달러
- 2015 : 321억 달러
- 2016 : 480억 달러
- 2017 : 534억 달러
- KISTI (한국과학기술정보연구원)
- 국내 시장은 2015년 2억 6300만 달러, 2020년 9억 달러로 성장
- 국내 IT 시장에서 빅데이터가 차지하는 비중은 2013년 0.6%에서 2020년 2.6%까지 증가
- 한국 빅데이터 시장
- 2013년 예측치 : 1억 6300만 달러
- 2015년 3000억 (2억 6300만 달러)
- 2020년 9000억 (8억 500만 달러) (70% 후반의 고성장)
- 한국 ICT에서 비중 : 2013. 0.6%, 2020. 2.3%
- 세계 빅데이터 시장의 1.6% 비중 점유


- 공공 빅데이터 시장은 2014년부터 고성장을 시작해 향후 5년간 5000억원 규모로 성장할 것
시장 현황
- 시장 현황
- 미래창조과학부 (미래부)
- 빅데이터 분석/활용 센터 구축 : 2013.9 ~,
- 빅데이터 마스터 플랜 수립 : 2016년까지 민간/정부가 약 5000억원을 빅데이터 기반 조성에 투입
- 빅데이터 아카데미 개설 : 2013년 100명 양성, 2007년까지 2000명 양성
- 빅데이터 기술 전문가, 빅데이터 분석 전문가
- 빅데이터 활용 시범사업
| 과제 | 상세 |
| 심야버스 노선 수립 지원 |
|
| 질병 주의, 예보 서비스 |
|
| 의약품 안전성 조기경보 서비스 |
|
| 의료 서비스 |
|
| 점포 이력 분석 서비스 |
|
| 지능형 뉴스 검색 서비스 |
|
- 우정사업정보센터
- 우편 서비스 빅데이터 기반 마련 및 활용
- 안행부
- 빅데이터 공통 기반 및 시범서비스 구축 (40억)
- 정부통합전산센터 : 클라우드 기반의 빅데이터 분석 파일럿 시스템 구축 사업 (12억)
- 한국과학기술정보연구원 (KISTI)
- 국가 과학기술 빅데이터 거버넌스 구축 (7억)
- 서울시
- 2015년까지 빅데이터 기술을 시정에 도입
- 한국크라우드컴퓨팅연구조합
- 2013년 SW융합 역량강화 과정 사업자에 선정됨
- 2013년 하반기까지 클라우드, 빅데이터 전문 인력 720명 양성 계획, 2013.06
BigData 도입 사례
| 업체 | 제품 | 상세 |
| GS홈쇼핑 | FOSS |
|
| 엔씨소프트 | FOSS |
|
| 삼성전자 |
| |
| 유유제약 |
| |
| KTH | Daisy |
|
| 삼성SDS |
| |
- 다음소프트, 소셜메트릭스 : 블로그, 트위터를 분석한 모니터링 정보 제공
- 코난테크놀러지, 펄스K : 소셜 미디어 모니터링 및 분석 서비스
- Google Trends : 검색 로그 기반 동향 분석
- Naver Trand
- BigData 관련 기관
- 서울대
- 빅데이터 센터
- 빅데이터 포럼 (2013.5.30) : 9개 전문 분과로 운영
- 빅데이터 인프라 기술, 데이터 과학 및 분석 기술, 법 정책, 보건의료, 생명 환경, 사회복지, 미래산업경제, 방송 문화 스포츠, 인프라 및 인력양성
산업별 적용 모델
- 참고 문헌
- http://www.zdnet.co.kr/news/news_view.asp?artice_id=20130328154732
- http://www.itworld.co.kr/m/news/154/81787/%EB%B6%80%EC%84%9C%EB%B3%84%20%EB%B9%85%20%EB%8D%B0%EC%9D%B4%ED%84%B0%20%EA%B8%88%EA%B4%91%20%EC%B0%BE%EA%B8%B0...%20%EB%B9%85%20%EB%8D%B0%EC%9D%B4%ED%84%B0%20ROI%20%EC%97%B0%EA%B5%AC%20%EB%B8%8C%EB%A6%AC%ED%95%91
- 산업별 BigData 적용 모델
| 산업군 | 상세 |
| 금융 |
|
| 공공 |
|
| 통신 |
|
| 유통 |
|
| 제조 |
|
- BigData 활용 분야
| 분야 | 상세 |
| 미래 예측 |
|
| 숨은 요구 발견 |
|
| 위험 감소 |
|
| 맞춤형 서비스 |
|
| 실시간 대응 |
|
- 정보 검색 서비스 -> 정보 분석 서비스
- 정보의 종류 : 공개된 SNS 정보, 미공개된 기업내 정보
- 다음소프트, 솔트룩스, 삼일 PwC, SKT 스마트 인사이트, 마스터카드
- 비씨카드 상권분석, 현대카드 상권분석 <- 여신전문금융업법 개정
- BigData 분석 플랫폼 제공
- KT 맵리듀스
- BigData 분석 방법론 제공
- 연관 관계, 의미
로그 분석 시장
- 참고 문헌
개발 환경 구성
- hadoop
- conf/*
- *.jar, lib/*.jar
- zookeeper
- zookeeper-3.4.5.jar
BigData Sizing
- Sizing 기준
- BigData 구분 기준 : 100 TB 이상
- BigData 샘플 분석 크기 : 100 GB
- BigData 시스템 규모 : 1 TB ~ 10 TB 처리 (55%)
- Core당 4 GB Memory
- Slave node당 24 TB Disk
- Esper : Dual CPU * 2 GHz : 초당 50만건 이상의 처리 성능과 평균 3 microseconds 이하로 처리
- BigData Server 구성 (250 TB당 20대)
- Admin Node * 1
- Working Node * 1
- Database Node * 2
- 수집/연동 Node * 2
- Master Node * 2
- Slave Node * 12
- 미래부, 빅데이터 시범센터
- 2013년 6월초 사업자 선정
- 2013년 9월 서비스
- 프로젝트 기간 : 3개월, 예산 : 8억 2000만원
- 추정 S/W : 38,294만원
- 추정 스토리지 : 27,306만원
- 추정 서버 : 13,694만원
- 추정 네트워크 :5412만원
- Oracle BigData Appliance
- Rack : Intel Xeon E5-2600 processor / 2 CPU * 8 Core
- 18 Server / 2 CPU * 8 Core / 64 GB Mem. / 12 * 2TB Disk / 10GBE
- Total 1152 GB Memory, 432 TB Disk
- $450,000, 년간 유지보수 비용 $54,000
- 5분이내에 처리 가능한 수천개의 jobs by facebook
- ~ 350 TB : 20+ nodes
- ~ 500 TB : 40+ nodes
- 참고 문헌
- SIZING BIG DATA PROBLEMS
- rows * columns / sec : 초당 처리해야 하는 행 * 열의 수
- Volume : rows가 1000만건 미만, 1000만건 이상에서 1억건 미만, 1억건 이상
- Velocity : 시간 단위, 분단위, 초단위
- Variety : columns이 100 미만, 100 이상에서 1000 미만, 1000 이상
단위 테스트
- Hadoop 테스트
성능 테스트
- Hadoop 벤치마킹 (Benchmark)
- MR Bench, TeraSoft, TeraGen, DFSIO
- Ganglia
- Hibench
- 속도 측정 단위
- 밀리초(ms) : 1/1,000초
- 마이크로초(μs) : 1/1,000,000초
- ms : 밀리초 0.001 = 10^(-3)초
- ㎲ : 마이크로초 0.000001초 = 10^(-6)초
- 참고 문헌
Turning
- Linux 2.6.30 이상 권장
- Local file system (ext3 or xfs) : mounted with noatime attribute
- nodiratime attribute
- File system read-ahead buffer size : 1024 or 2048 sectors
- Hadoop 설정
dfs.namenode.handler.count = 64 이상 (default. 10) //--- Numbers of name node and job tracker server threads dfs.datanode.handler.count = 8 이상 (default. 3) //--- Numbers of data node server threads dfs.replication = 3 //--- replication factor for each block of an HDFS dfs.block.size = 128 MB or 256 MB (default. 64 MB) //--- HDFS block size mapred.job.tracker.handler.count = 64 이상 (default. 10) //--- Numbers of name node and job tracker server threads //--- Maximum number of map/reduce tasks mapred.tasktracker.map.tasks.maximum = node당core수 / 2 ~ node당core수 * 2 mapred.tasktracker.reduce.tasks.maximum = node당core수 / 2 ~ node당core수 * 2 mapred.compress.map.output = enabled //--- Compression of intermediate result and final output mapred.output.compress = enbaled //--- Compression of intermediate result and final output mapred.map.output.compression.codec = LZO //--- Compression of intermediate result and final output mapred.output.compress.codec = LZO //--- Compression of intermediate result and final output mapred.reduce.parallel.copier = 16 ~ 25 (default. 5) //--- Number of parallel copier threads during reduce shuffle phase tasktracker.http.threads = 40 ~ 50 //--- Number of work threads on HTTP server java.net.preferIPv4Stack = true io.sort.factor = 100 이상 //--- Number of input streams files to be merged at once io.sort.mb = 200 MB (default. 100MB) //--- Total size of result and metadata buffers associated with a map task io.sort.record.percent = 조정 (default. 0.05) //--- Percentage of total buffer size that is dedicated to the metadata
- Java 6 (Java 6u12) 이상
- vi /etc/security/kimits.conf
- Open file descriptor limit : 64000
- vi /etc/sysctl.conf
- Open epoll file descriptor limit : 4096
IP로 위치 추적
내 IP 확인
- 내 아이피 확인 / 위치보기
IP로 주소 확인
- IP 조회
- 해외 IP 조회
- 국가별 IP 대역
- http://domain.kisa.or.kr/jsp/ipas/situation/listIpv4.jsp 사이트에서 대한민국의 IP 대역을 Excel로 다운로드 받을 수 있습니다.
- GeoIP : MaxMind에서 제공하는 국가별로 IP를 확인할 수 있는 오픈소스 라이브러리
- 데이터 베이스 다운로드 : http://www.maxmind.com/en/home
- 사설 IP 대역
- A class : 10.0.0.0∼10.255.255.255 (10/8 prefix)
- B class : 172.16.0.0∼172.31.255.255 (172.16/12 prefix)
- C class : 192.168.0.0∼192.168.255.255 (192.168/16 prefix)
- Splunk의 iplocation 검색 명령어
- http://www.hostip.info/, http://www.hostip.info/use.html
- http://api.hostip.info/country.php?ip=12.215.42.19
- http://api.hostip.info/get_html.php?ip=12.215.42.19 : Country, City 반환
- http://api.hostip.info/get_html.php?ip=12.215.42.19&position=true : 위도와 경도도 추가로 반환
- http://api.hostip.info/get_json.php?ip=12.215.42.19
- http://api.hostip.info/get_json.php?ip=12.215.42.19&position=true
- http://api.hostip.info/?ip=12.215.42.19
Country: TAIWAN (TW) City: (Unknown city) IP: 203.222.12.34
주소로 위도/경도 좌표 확인
- 지오코딩 (GeoCoding) : 주소를 위도/경도와 같은 좌표로 변환
- 네이버 지도 Open API
- 검색 API의 경우 키 당 일일 25,000 쿼리, 지도 API의 경우 일일 100,000 페이지 요청까지 지원
- 추가 사용이 필요할 경우, Naver Open API 제휴 신청을 하세요.
- http://dev.naver.com/openapi/apis/map/javascript_2_0/reference#coordtrans
- tm128 좌표로 위치를 반환하는 Sample : http://openapi.map.naver.com/api/geocode.php?key=test&encoding=utf-8&coord=tm128&query=경기도성남시정자1동25-1
- 1일 2500개 사용 제한, Google Maps API for Business 사용자는 하루에 최대 100,000개
- http://maps.googleapis.com/maps/api/geocode/json?sensor=false&address=대한민국 서울특별시 관악구 낙성대동 1599-3
- http://maps.googleapis.com/maps/api/geocode/json?sensor=false&address=대한민국서울특별시관악구낙성대동1599-3
- http://maps.googleapis.com/maps/api/geocode/json?latlng=37.4794312,126.9534629&sensor=false
- https://maps.google.com/maps?hl=kr 사이트에서 지도를 오른쪽 마우스로 클릭한 후 "이곳이 궁금한가요?" 메뉴를 선택하면 검색창에 GPS 좌표가 표시 됩니다.
- 참고 문헌
위도/경도 좌표로 지도 표시
- http://maps.yahoo.com/#q1=대한민국 서울특별시 관악구 봉천동&mag=6&lon=경도&lat=위도
공공 정보 개방 현황
- 2013.7.30 : 공포
- 2013.10.31 : 시행
- 공공정보 개방 현황
- 608기관 1718종 17,065,215건 (2013.08)
- 대한민국 : https://www.data.go.kr/
- 미국 : http://www.data.gov/
- 영국 : http://www.data.gov.uk/
- 호주 : http://data.gov.au/, http://data.australia.gov.au/
- 참고 문헌
빅데이터 소스
- 공공데이터포털 : 교육, 교통물류 등 18종, 16880건
- 서울 열린 데이터 광장 : 공공행정, 교육 등 9종 , 9128건
- 데이터스토어 : 과학기술, 교통물류 등 15종, 6358건
- API STORE : 공공행정, 교통물류 등 8종, 227건
- 경기데이터드림 : 공공행정, 농축수산 등 10종, 1065건
- 빅데이터 샘플 Data Set 다운로드 사이트
- http://www.findbestopensource.com/article-detail/free-large-data-corpus
- http://blogs.msdn.com/b/avkashchauhan/archive/2012/04/12/processing-million-songs-dataset-with-pig-scripts-on-apache-hadoop-on-windows-azure.aspx
- http://labrosa.ee.columbia.edu/millionsong/
- http://www.infochimps.com/collections/million-songs
참고 문헌
- 21세기 원유, 빅데이터의 가능성, 2013.04
- 빅데이터 교육, 2013.2 : BigData 교육 목차