문자셋과 인코딩
문자셋과 인코딩에 대해 설명하고 다양한 환경에서 한글 문제에 대한 해결책을 제시한다.
우리나라도 이제 국제화에 눈을 떠서 다양한 언어를 지원해야 하므로 UTF-8을 기준으로 하여 작성한다.
목차
문자셋과 인코딩
문자셋과 인코딩의 정의
- 문자셋 (charset, Character Set)
- 하나의 언어권에서 사용하는 언어를 표현하기 위한 모든 문자(활자)의 모임을 문자셋이라고 합니다. 다시 말하면 우리가 얘기하는 언어를 책으로 출판할 때 필요한 문자(활자)를 모두 모은 것이라고 보면 됩니다. 그러므로 부호와 공백 등과 같은 특수 문자도 문자셋에 포함 됩니다.
- 영어의 경우 알파벳 대소문자와 특수 문자 등으로 간단하게 문자셋을 구성할 수 있지만 한글의 경우 출판에서 가나다 등으로 출판함으로 훨씬 다양한 문자셋을 가지고 또한 한자를 병행해서 사용함으로 문자셋의 범위는 더욱 넓어 집니다.
- 추상적인 글자 셋으로 여러개의 인코딩을 가질 수 있습니다.
- MIME 문자셋은 IANA에서 정의하며 인터넷 및 XML 파일에서 사용 합니다.
- 인코딩 (encoding)
- 인코딩은 문자셋을 컴퓨터가 이해할 수 있는 바이트와의 매핑 규칙 입니다. 예를 들면 ASCII Code에서 ABC 등은 문자셋이고 A는 코드 65, B는 코드 66 등 바이트 순서와 매핑한 것이 인코딩 입니다. 따라서 문자셋을 어떻게 매핑 하느냐에 따라 하나의 문자셋이 다양한 인코딩을 가질 수 있습니다.
- 추상적인 문자셋을 구체적인 bit-stream으로 표기하는 방법 입니다.
- 여러가지 문자셋을 동시에 표시할 수 있습니다.
- 대부분의 인코딩에서는 대소문자를 구분하지 않습니다.
- 대한민국에서 가장 많이 사용하는 인코딩은 "UTF-8", "KSC5601", "ISO-8859-1" 입니다.
- 문자셋(인코딩)의 예
- 한글 : 8bit KSC5601 (8bit EUC-KR, 7bit ISO-2022-KR, ISO-2022-Int)
- 영문 : KSC5636, US-ASCII (둘 간의 차이는 화페 단위 뿐)
- 한글+영문 : KSC5861 (EUC-KR), KSC5636 + KSC5601를 모두 포함한다.
- 유니코드 : 4byte Unicode < ISO-10646 UCS (ISO-8859-1, UTF-8, UTF-16)
문자셋과 인코딩은 동일한 명칭을 가질 수 있어 서로 혼용하여 사용되는 경우가 많다.
EUC-KR은 원래 유닉스용 표준이었는데 인터넷으로 확장되어 사용 됩니다.
KSC5601은 인터넷에서 원활한 한글(완성형) 사용을 위하여 정의된 표준 입니다.
EUC (Extended UNIX Code), UTF (UCS Transformation format)
기본 인코딩
- Windows : 시스템 언어와 관련된 코드 페이지를 따름
- 영문 Windows는 CP1252 인코딩을 사용
- 한글 Windows는 MS949 인코딩을 사용
- Unix : LANG 환경 변수로 지정된 로케일에 해당하는 인코딩
- Solaris는 LANG 환경 변수가 ko, ko_KR일 경우 EUC-KR 인코딩을 사용
- HP는 LANG 환경 변수가 ko_KR, ko_KR.eucKR일 경우 EUC-KR 인코딩을 사용
- Unix에서 locale -a 명령을 사용하여 LANG 환경 변수에 지정 가능한 문자셋을 확인할 수 있다.
- ksh 환경에서 환경 변수 설정 예
LANG=ko_KR.utf8 export LANG
- csh 환경에서 환경 변수 설정 예
set LANG ko_KR.utf8 setenv LANG ko_KR.utf8
- HTML : ISO-8859-1와 ISO-10646
- XML : UTF-8
- 웹 브라우져 : 내부적으로 모두 유니코드로 처리를 한다.
- HTTP/1.0 : ISO-8859-1
- HTTP (URL,URI) : US-ASCII, %hexadecimal_code, JavaScript escape() 함수 사용
- Java : 유니코드 2.0
- 직렬화된 Java Class : UTF-8
- J2EE : ISO-8859-1
- Oracle : UTF-8 (AL32UTF8), 한국에서는 KSC5601 (KO16KSC5601)

Java에서 Encoding 확인
- WEB/WAS에서 JSP 파일이 UTF-8인 환경에서 인코딩을 확인한다. (Media:ChkEncoding.zip)
- 첨부된 zip 파일을 다운로드하여 압축을 풀어 UTF-8 인코딩으로 작성된 ChkEncoding.jsp 파일을 생성한다.
- ChkEncoding.jsp 파일을 WEB/WAS의 Document Root 디렉토리로 복사한다.
- ChkEncoding.jsp을 실행하여 UTF-8 환경에서 정상적으로 처리되는 인코딩을 확인한다.
- WEB/WAS에서 JSP 파일이 KSC5601인 환경에서 인코딩을 확인한다. (Media:ChkEncodingKo.zip)
- 첨부된 zip 파일을 다운로드하여 압축을 풀어 KSC5601 인코딩으로 작성된 ChkEncodingKo.jsp 파일을 생성한다.
- ChkEncodingKo.jsp 파일을 WEB/WAS의 Document Root 디렉토리로 복사한다.
- ChkEncodingKo.jsp을 실행하여 KSC5601 환경에서 정상적으로 처리되는 인코딩을 확인한다.
다양한 환경에서 인코딩 설정
웹 브라우져 설정
- "도구 -> 인터넷 옵션 -> 언어" 메뉴를 선택한다.
- 영어[en]와 한국어[ko]를 추가하고 원하는 언어를 가장 상단에 위치한다.
JVM 설정
- 일반적으로 LANG 환경 변수를 설정해 주면 자동으로 설정 됩니다.
locale -a Linux 명령어로 지원 가능한 encoding을 확인 합니다. set LANG ko csh에서 Encoding을 설정 합니다. (KSC5601, EUC-KR) setenv LANG ko LANG=ko ksh에서 Encoding을 설정 합니다. (KSC5601, EUC-KR) export LANG
- JVM 옵션 설정 (UTF-8, ISO-8859-1, KSC5601)
-Dfile.encoding=8859_1 필수 항목 -Dfile.client.encoding=8859_1 -Dclient.encoding.override=8859_1 JVM 버전에 따라 (사용안함)
- JSP를 사용하여 JVM 옵션 확인 (encoding.jsp)
file.encoding = <%= System.getProperty("file.encoding") %><br>
file.client.encoding =
<%= System.getProperty("file.client.encoding") %><br>
client.encoding.override =
<%= System.getProperty("client.encoding.override") %><br>
HTML 설정
HTML 파일을 UTF-8로 만들어 저장한다.
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
XML 설정
XML 파일을 UTF-8로 만들어 저장한다.
<?xml version="1.0" encoding="UTF-8" ?>
JSP 설정
JSP 파일을 UTF-8로 만들어 저장한다.
<%@ page pageEncoding="UTF-8" %> <%@ page contentType="text/html;charset=UTF-8" %>
Servlet 설정
HTTP 요청의 인코딩 지정
request.setCharacterEncoding("UTF-8");
HTTP 응답의 인코딩 지정
response.setContentType("text/html; charset=UTF-8");
web.xml 설정
<mime-mapping>
<extension>html</extension>
<mime-type>text/html;charset=UTF-8</mime-type>
</mime-mapping>
Default Oracle Database 문자셋
- Default Oracle Database 문자셋 : UTF-8 (AL32UTF8), 한국에서는 KSC5601 (KO16KSC5601)
- AL32UTF8, KO16KSC5601 (KSC5601), WE8ISO8859P1 (8859_1)
- Default Oracle Database 문자셋 확인 방법
sqlplus system/manager
select parameter || ' : ' || value parameter_value
from NLS_DATABASE_PARAMETERS
where parameter = 'NLS_CHARACTERSET'
or parameter = 'NLS_NCHAR_CHARACTERSET';
select name || ' : ' || substr(value$, 1, 40) parameter_value
from sys.props$
where name = 'NLS_CHARACTERSET';
select parameter || ' : ' || value parameter_value
from NLS_INSTANCE_PARAMETERS, V$NLS_PARAMETERS, NLS_SESSION_PARAMETERS;
- Oracle Database 문자셋 변경 방법
- 환경 변수 또는 %ORACLE_HOME%/dbs/init[SID].ora 을 설정한다.
NLS_LANG='American_America.Ko16ksc5601' ORA_NLS33='$ORACLE_HOME/ocommon/nls/admin/data' NLS_DATE_FORMAT='YYYY-MM-DD'
- DriverManager에서 문자셋 설정 방법
java.util.Properties props = new java.util.Properties();
props.put("charSet", "KSC5601" );
DriverManager.getConnection(dbUrl, props);
PHP
지금은 국제화 시대이므로 UTF-8을 기준으로 한글 설정을 한다. 아래 자료는 PHP 5.2.8을 기준으로 작성 되었다.
- PHP에서 한글화를 위해 필요한 모듈
- iconv
- mbstring
- $PHP_HOME/php.ini 에서 다음과 같이 수정 한다.
[PHP] default_charset = "UTF-8" magic_quotes_gpc = Off output_buffering = 4096 output_handler = mb_output_handler [mbstring] mbstring.language = UTF-8 mbstring.internal_encoding = UTF-8 mbstring.http_input = auto mbstring.http_output = UTF-8 //--- PDF 작성시 암호를 물어 보면 pass 로 설정하세요 mbstring.encoding_translation = On mbstring.detect_order = auto mbstring.substitute_character = none; ; mbstring.encoding_translation = Off //--- HTTP 입력 변환을 무효화 [PHP_MBSTRING] extension=php_mbstring.dll #--- CentOS에서는 이 부분 대신 /etc/php.d/mbstring.ini 파일이 존재 합니다.
참고 문헌
Perl
Python
- UTF-8을 기준으로 하여 Python 파일(~.py)에서 한글 설정
- Python 파일(~.py)을 UTF-8 형태로 저장 한다.
- "# -*- coding: utf-8 -*-" 문자열을 Python 파일(~.py) 최상단에 배치 한다.
import sys
reload(sys)
sys.setdefaultencoding('utf8')
Eclipse IDE
- "Window -> Preferences -> General -> Workspace" 메뉴에서 "Text file encoding"을 "UTF-8"로 설정 합니다.
- Package Explorer에서 패키지명을 오른쪽 마우스로 클릭 합니다.
- "Properties -> Resource" 메뉴에서 "Text file encoding"을 "UTF-8"로 설정 합니다.
- Package Explorer에서 임의의 프로그램을 오른쪽 마우스로 클릭 합니다.
- "Run As -> Run Configurations..." 메뉴를 선택 합니다.
- "Arguments" 탭에서 "VM arguments"에 "-Dfile.encoding=UTF-8"를 추가 합니다.
- "Common" 탭에서 "Encoding"을 "UTF-8"로 설정 합니다.
- ~.properties 파일을 깨어지지 않은 형태로 보고 싶을 경우
- "Help -> Install New Software..." 메뉴를 선택 합니다.
- "Add..." 버튼을 눌러 다음과 같이 입력한 후 Property Editor를 설치 합니다.
- Name : Propedit
- Location : http://propedit.sourceforge.jp/eclipse/updates/
- Java Compile과 실행시 아래와 같이 설정 합니다.
- 예) %JAVA_HOME%\bin\javac -source 1.6 -target 1.6 -encoding UTF-8 -d %WSC_TARGET% %WSC_SRC%/com/jopenbusiness/sfdc/wsc/Sample.java
- 예) %JAVA_HOME%\bin\java -version:1.6 -Dfile.encoding=UTF-8 com.jopenbusiness.sfdc.wsc.Sample
- ANT 사용시 java task 사용시 다음을 추가 합니다.
- <jvmarg value="-version:1.6" />
- <jvmarg value="-Dfile.encoding=UTF-8" />
RStudio
- R의 디폴트 인코딩 정보 확인
- R 내부에서 문자열을 저장할 때 사용하는 인코딩 정보를 표시 합니다.
- R에서 지원하는 인코딩 : latin1, UTF-8, bytes
localeToCharset()[1] Sys.getlocale()
- 데이터로 저장된 문자열의 인코딩 정보 확인
Encoding(~)
- 문자열의 인코딩 변환
- CP949"로 인코딩된 ~라는 데이터에 저장된 문자열을 "UTF-8"로 인코딩된 문자열로 변환
iconv(~, "CP949", "UTF-8)
- R의 오류 메시지를 영문으로 보기
- 영문 오류 메시지가 명확하고 구글 등의 검색을 통해서 확인하기가 편리 합니다.
Sys.setlocale("LC_ALL", "English_United States.1252") #--- 영문 문자셋을 지정 합니다.
Sys.setlocale() #--- 원래 디폴트로 설정된 문자셋으로 복구 합니다.
- RStudio에서 ~.R 파일의 디폴트 인코딩을 "UTF-8"로 설정
- "Tools -> Global Options..." 메뉴를 선택한 후 "General" 메뉴를 선택 합니다.
- "Default text encoding: " : "UTF-8"을 선택 합니다.
- 파일에 있는 문자열 읽기
- "UTF-8"로 인코딩된 파일이고 R의 디폴트 인코딩이 "CP949"일 경우
- fileEncoding : 파일의 인코딩 정보
- encoding : 최종적으로 R에 저장할 때 적용할 인코딩 정보
(data <- read.table("data/zztemp.csv", header=TRUE, sep=",",
stringsAsFactors=FALSE, na.strings=c('NIL'), comment.char="#",
fileEncoding="UTF-8", encoding="CP949"))
- 파일로 저장
write.table(data, file="data/zztemp.csv", row.names=FALSE, sep=",",
append=FALSE, quote=FALSE, fileEncoding="UTF-8")
- KoNLP 로딩시 오류 발생할 경우
library(KoNLP) #--- JAVA_HOME 설정을 JDK에서 JRE로 변경 하세요. (bin/server/jvm.dll 파일 등을 사용함)
- 한글을 직접 사용할 경우에는 정상 처리되나 변수에 담긴 한글을 사용할 때 오류가 발생할 경우
- 원인 : 변수에 담긴 한글은 인코딩 정보가 포함 되어 있어 이를 처리하려다 오류가 발생함
- 조치 : enc2native(한글_변수) 를 사용하여 인코딩 정보를 없애주면 됩니다.
서비스에서 인코딩 설정
MySQL에서 UTF-8 설정
- 다중 언어를 지원하기 위해서 UTF-8 charset을 설정한다.
- MySQL이 설치된 홈디렉토리에 있는 my-medium.ini 파일을 복사하여 my.ini 파일을 생성한다.
- my.ini 파일에 아래 사항을 추가 또는 수정한다.
[mysql] default-character-set=utf8 [mysqld] character-set-client-handshake=FALSE init_connect="SET collation_connection=utf8_general_ci" init_connect="SET NAMES utf8" default-character-set=utf8 //--- Ubuntu Server 13.04에서는 오류가 발생함 character_set_client=utf8 character-set-server=utf8 collation-server=utf8_general_ci [client] default-character-set=utf8 [mysqldump] default-character-set=utf8
- "MySQL Administrator -> Tools -> MySQL Command Line Client"에서 다음 명령을 사용하여 인코딩을 확인한다.
show variables like "%char%"; show variables like "%collation%";
- PHP 연동시 한글 설정
$dbconn = mysql_connect("localhost", "root", "암호");
$dbselect = mysql_select_db("your_db_name", $dbconn);
mysql_query("set names euckr;"); //--- DB가 KSC5601일 경우
mysql_query("set names utf8;"); //--- DB가 UTF-8일 경우
CentOS 7에서 MariaDB의 UTF-8 설정
CentOS 7에 설치된 MariaDB에서 UTF-8 설정
/etc/my.cnf.d/ 폴더 아래에 설정 파일이 있습니다.
- vi /etc/my.cnf
[mysql] default-character-set=utf8 [mysqld] datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 # Settings user and group are ignored when systemd is used. # If you need to run mysqld under a different user or group, # customize your systemd unit file for mariadb according to the # instructions in http://fedoraproject.org/wiki/Systemd init_connect="SET collation_connection=utf8_general_ci" init_connect="SET NAMES utf8" character-set-server=utf8 collation-server=utf8_general_ci skip-character-set-client-handshake #character-set-client-handshake=FALSE #default-character-set=utf8 #character_set_client=utf8 [mysqld_safe] log-error=/var/log/mariadb/mariadb.log pid-file=/var/run/mariadb/mariadb.pid [client] default-character-set=utf8 [mysqldump] default-character-set=utf8 # # include all files from the config directory # !includedir /etc/my.cnf.d
systemctl restart mariadb.service
- 설정 확인
mysql -u root -p mysql
show variables like 'c%';
quit
CentOS에서 MariaDB의 UTF-8 설정
CentOS 6.5에서 MariaDB의 문자셋을 설정 합니다.
vi /etc/my.cnf.d/client.cnf
|
[client] |
vi /etc/my.cnf.d/mysql-clients.cnf
|
[mysql]
[mysqldump]
default-character-set = utf8 |
vi /etc/my.cnf.d/server.cnf
|
[mysqld] |
|
service mysql restart |
MySQL/CentOS에서 UTF-8 설정
- MySQL 문자셋 확인
mysql -uroot -p mysql show variables like 'c%'; exit
- 문자셋 확인 결과
+--------------------------+----------------------------+ | Variable_name | Value | +--------------------------+----------------------------+ | character_set_client | utf8 | | character_set_connection | utf8 | | character_set_database | utf8 | | character_set_filesystem | binary | | character_set_results | utf8 | | character_set_server | utf8 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | | collation_connection | utf8_general_ci | | collation_database | utf8_general_ci | | collation_server | utf8_general_ci | | completion_type | 0 | | concurrent_insert | 1 | | connect_timeout | 10 | +--------------------------+----------------------------+
- MySQL 문자셋 설정
- vi /etc/my.cnf
[client] default-character-set = utf8 [mysqld] init_connect = "SET collation_connection = utf8_general_ci" init_connect = "SET NAMES utf8" default-character-set=utf8 //--- 오류가 발생하여 mysql 데몬이 기동되지 않을 경우 삭제 하세요. character-set-server=utf8 collation-server = utf8_general_ci [mysqldump] default-character-set = utf8 [mysql] default-character-set = utf8
- service mysqld restart
Apache/CentOS에서 UTF-8 설정
- vi /etc/httpd/conf/httpd.conf
LanguagePriority ko en ... #--- ko를 맨앞으로 위치 한다. AddDefaultCharset UTF-8
Tomcat에서 UTF-8 설정
- vi /etc/tomcat5/server.xml 파일을 UTF-8 Charset을 위해 다음과 같이 수정 한다.
#--- URIEncoding="UTF-8"을 추가한다.
<Connector port="8080" maxHttpHeaderSize="8192" URIEncoding="UTF-8"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true" />
<Connector port="8009" URIEncoding="UTF-8"
enableLookups="false" redirectPort="8443" protocol="AJP/1.3" />
- UTF-8 Charset을 위해 Tomcat의 Java 환경을 설정한다.
- "Apache Tomcat Properties" 창에서 "Java" 탭을 선택한다.
- Java Options에 다음을 추가한다.
-Dfile.encoding=8859_1 -Dfile.client.encoding=8859_1 -Dclient.encoding.override=8859_1
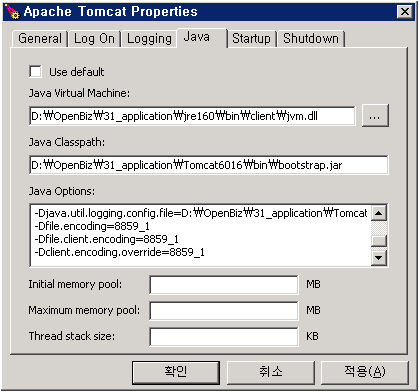
- "적용" 버튼을 눌러 변경 사항을 적용한다.

- vi /etc/tomcat5/tomcat5.conf 파일에 다음을 추가 한다.
JAVA_OPTS="$JAVA_OPTS -Dfile.encoding=8859_1 -Dfile.client.encoding=8859_1 -Dclient.encoding.override=8859_1" #--- 아래 라인 위에 위 라인을 추가 한다. JAVA_OPTS="$JAVA_OPTS -Dcatalina.ext.dirs=$CATALINA_HOME/shared/lib:$CATALINA_HOME/common/lib"
- Tomcat Connectors를 사용하여 Apache HTTP Server와 Apache Tomcat을 연동할 경우 환경 설정
- mod_jk.conf 설정 파일에서 다음 옵션을 추가 한다.
JkOptions +ForwardURICompatUnparsed
Hadoop에서 UTF-8 설정
- Hadoop 1.0
- vi conf/mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapred.child.java.opts</name> <value>-Xmx200m -Dfile.encoding=UTF-8 -Dfile.client.encoding=UTF-8 -Dclient.encoding.override=UTF-8</value> </property> </configuration>
Nginx에서 UTF-8 설정
Nginx에서 UTF-8을 설정하기 위해서는 http, server 또는 location에 charset UTF-8;을 추가 합니다.
vi /etc/nginx/nginx.conf
|
http { |
vi /etc/nginx/sites-available/ossnode101.conf
|
server { |
Nginx를 재기동 합니다.
|
service nginx restart #--- nginx -s reload curl -I http://localhost/ #--- 적용 상태 확인 |
터미널에서 한글 설정
- Telnet으로 Unix 사용시 한글이 보이나 입력이 안될 경우 설정
stty -istrip -parenb cs8
- 언어 설정 확인
#--- 사용 가능한 언어를 확인한다. locale -a env | grep LANG
Ubuntu Server 한글 설정
- vi /etc/default/locale
LANG="ko_KR.UTF-8"
CentOS 한글 설정
export LANG=ko_KR.utf8 export TZ='Asia/Seoul' # vi /etc/sysconfig/i18n # LANG="ko_KR.UTF-8"
locale -a 명령 입력시 "ko_KR.UTF-8"이 등록되어 있지 않은 경우 아래와 같이 설정 한다.
localedef -f UTF-8 -i ko_KR ko_KR.utf8 yum -y install google-noto-sans-korean-fonts
vi encoding 설정
vi ~/.vimrc " ****************************************************************************** " *** 프로그램 명 : .vimrc, Version 0.00.001 " *** 프로그램 설명 : vim 설정 " *** 작성자 : 산사랑 (consult@jopenbusiness.com, www.jopenbusiness.com) " *** 작성일 : 2016.7.27 ~ 2016.7.27 " *** --- [Copyright] ---------------------------------------------------------- " *** Copyright (c) 1995~2016 산사랑, All rights reserved. " ****************************************************************************** syntax on " 구문 강조 set nu " 라인 번호 표시 set ru " 커서 위치 표시 set ruler set showcmd set title set wmnu set showmatch " 호응하는 괄호 표시 set nocompatible set encoding=utf8 " 파일의 인코딩 설정 set ts=4 " Tab 사이즈 설정 set softtabstop=4 set shiftwidth=4 " Shift 사이즈 설정 set expandtab " set autoindent " 이전 줄에서의 글여쓰기를 유지 set smartindent " autoindent 보다 향상된 기능 제공
Putty 한글 설정
- "창 -> 변환" 메뉴에서 "수신한 데이터를 이 문자셋으로 가정" 값을 UTF-8로 설정 합니다.
- 영문 putty의 경우 "Window -> Translation" 메뉴에서 "Remote character set"을 UTF-8로 설정 합니다.
인코딩 관련 Utility
JVM을 이용한 파일 코드 변환
EUC-KR 파일(file.euc_kr)을 UTF-8 파일(file.utf8)로 변환한다.
native2ascii -encoding EUC_KR file.euc_kr file.tmp native2ascii -reverse -encoding UTF8 file.tmp file.utf8
iconv를 사용한 파일 코드 변환
- index.hhc 파일을 UTF-8에서 CP949로 변환할 경우
iconv -f UTF-8 -t CP949 index.hhc > index.cp949
파일 코드 변환
일반적으로 사용하는 인코딩 : "UTF-8", "KSC5601", "ISO-8859-1"
//--- Java 함수
public boolean encodingFile(String encodeFr, String encodeTo)
throws IOException
{
InputStreamReader inp =
new InputStreamReader(System.in, encodeFr);
OutputStreamWriter out =
new OutputStreamWriter(System.out, encodeTo);
for (int ch;(ch = inp.read()) != -1;) {
out.write(ch);
if (ch == 0xfffd) {
//--- 오류 : 유니코드로 표현할 수 없는 문자임
inp.close();
out.close();
return false;
}
}
out.close();
inp.close();
return true;
}
Java에서 코드 변환
public static String encoding(String str, String encodeFr,
String encodeTo)
{
try {
return new String(str.getBytes(encodeFr), encodeTo);
} catch(Exception ex) {
return str;
}
}
public static String java2db(String str)
{
return encoding(str, "ISO-8859-1", "KSC5601");
}
public static String db2java(String str)
{
return encoding(str, "KSC5601", "ISO-8859-1");
}
Applet을 사용한 한글 parameter 전달 방법
- Encoder.java라는 Applet을 작성한다.
- 웹서버 홈 디렉토리 아래에 applets 폴더를 만든다.
- Encoder.java를 컴파일한 Encoder.class 파일을 applets 폴더에 위치한다.
import java.applet.Applet;
import java.net.URLEncoder;
public class Encoder extends Applet
{
public Encoder()
{
}
public void init()
{
}
public String encode(String s)
{
return URLEncoder.encode(s);
}
}
- HTML에서 Applet을 사용하여 한글 parameter를 전달한다.
- HTML에 다음과 같이 Applet을 포함한다.
<applet id="Encoder" name="Encoder" codebase="/applets"
code="Encoder.class" width="0" height="0" MAYSCRIPT>
</applet>
<script type="text/JavaScript">
function URLEncode(str)
{
return window.document.all["Encoder"].encode(str);
}
</script>
- JavaScript에서 Applet을 사용하여 한글을 encoding하여 전달한다.
예) window.document.location.href =
"/test.jsp?name=" + URLEncode("한글");
- 서버의 Servlet 또는 JSP에서 전달된 Parameter를 decode하여 사용한다.
import java.net.URLDecoder;
URLDecoder.decode("전달받은 parameter");
CFLF 변환
LF : Line Feed (\n)
CR : Carriage Return (\r)
Windows는 CRLF를 사용하고 Linux는 LF만 사용하므로 변환을 시켜주어야 합니다.
Linux에서 변환
yum -y install dos2unix
dos2unix 파일명
tr -d '\r' < input.file > output.file
sed 's/^M$//' input.txt > output.txt
폰트
글꼴의 종류
| 글꼴 종류 | 설명 |
| 비트맵 글꼴 |
|
| 타입1 글꼴 |
|
| 타입3 글꼴 |
|
| 트루타입 글꼴 |
|
| 타입42 글꼴 |
|
| 메타 글꼴 |
|
| 글꼴 족 |
|
무료 글꼴
| 글꼴 | 설명 |
| 나눔고딕 코딩글꼴 |
|
| 네이버 나눔 글꼴 |
|
- 글꼴 모음
- 나눔고딕 코딩 글꼴
- 네이버 나눔글꼴
- 또 하나의 무료 한글 폰트, 렉시 굴림
- 앗! 무료 한글 폰트가 이렇게 많다니!!! 2 : 28종류의 무료 글꼴 소개
- 130종 이상의 무료 한글 폰트 받기
오픈소스 한글화
참고 문헌
- WebLogic Server의 국제화
- http://java.freehosting.co.kr/java/messages/1597.html
- http://www.w3c.or.kr/i18n/
- 문자셋, 인코딩 이야기
- ASCII 코드표